

Summarize and analyze this article with
The 5 pillars of data observability — freshness, volume, schema, lineage, and distribution — define what every modern monitoring platform watches for. They do not define what an enterprise data team needs to monitor in 2026. Two more pillars — pipeline and cost — close that gap. Here is the seven-pillar framework, and the operating layer that makes it work.
Where the five pillars came from, and why two more are needed
The original five-pillar framework was published by Monte Carlo in 2020 and has been the canonical definition of data observability ever since. Freshness, volume, schema, lineage, distribution. Five table-level signals that catch most of what breaks in a well-designed pipeline. Almost every observability platform in the market today is built around some subset of those five.
The framework was correct for the problem it was built to solve. In 2020, the modern data stack was new, table-level data quality was the dominant failure mode, and the cloud warehouse was usually the single hardest dependency a data team owned. Detecting null spikes, schema drift, and freshness breaches on a dozen critical tables was enough to keep most teams out of trouble.
That is not the problem in 2026. Enterprise data teams now own pipelines that span Snowflake, Databricks, on-prem feeds, real-time Kafka queues, and AI consumers that ingest data automatically with no human checkpoint. Cloud spend has become a board-level concern: a runaway query that scans a 50TB table can cost more than a missing record. And the pipelines that move data have become observability surfaces in their own right — when an Airflow DAG silently degrades from a 12-minute runtime to 45 minutes, every downstream consumer is affected, but none of the five canonical pillars catch it.
Two more pillars close that gap. Pipeline observability covers the system that moves the data, separately from the data itself. Cost observability covers the financial behavior of the platform, treated as a first-class signal rather than a monthly bill. Together, the seven pillars cover what an enterprise data team actually needs to monitor — not what 2020’s modern data stack used to need.
Pillar 1 — Freshness
Freshness asks one question: did the data arrive on time? Every pipeline has an expected cadence — hourly, daily, weekly, on-demand — and a freshness pillar continuously checks whether new rows landed within the agreed window. A breach can mean an upstream source went down, an orchestrator stalled, or a transform job failed silently.
The mechanics are straightforward. Track the last successful update timestamp per table or dataset, compare it against the SLA, alert when the gap exceeds tolerance. Most observability platforms expose this as a per-asset metric with configurable thresholds.
Where freshness alone falls short is in cost-of-failure. A freshness breach on a developer’s sandbox table is noise. The same breach on revenue_daily thirty minutes before a CFO opens the executive dashboard is a Sev-1 incident. Freshness as a raw signal tells you the data is late. It cannot tell you whether being late matters. That gap is where the operating layer comes in — but that is a conversation for later in the article. The pillar itself, treated correctly, gives you the leading indicator. The downstream cost of staleness sits in the dedicated data downtime discussion.
Pillar 2 — Volume
Volume tracks how much data arrives, every time data arrives. The signal is row-count consistency relative to a historical baseline: if the last thirty daily loads averaged 4.2M rows with a standard deviation of 200K, today’s load of 1.1M rows is an anomaly worth flagging before any downstream consumer sees it.
Volume is the pillar that catches the failures freshness misses. A pipeline can run on time and still drop 80% of its records — the orchestrator reports success, freshness passes, and a partial dataset propagates downstream as if it were complete. Volume observability is the second line of defense.
The signal also runs in both directions. Sudden drops usually point to source-side problems: an API rate limit, a deprecated endpoint, a partition that never landed. Sudden spikes usually point to a logic bug: a JOIN that turned into a Cartesian product, a deduplication step that no longer dedups, a backfill that re-ran without a watermark.
The example most teams recognize: a 58% volume drop on orders_staging early in the morning. Freshness passes because the file landed. Schema passes because columns are intact. Only volume catches it — and only volume catches it in the hour between landing and consumption, while there is still time to act.
Pillar 3 — Schema
Schema observability monitors structural changes to a dataset — columns added, columns dropped, types changed, constraints loosened. A column renamed from customer_id to cust_id in an upstream source breaks every join that references the old name. A field cast from INTEGER to STRING corrupts every downstream aggregate. A primary-key constraint silently dropped allows duplicate records that pollute every dashboard built on top.
The signal is detected by comparing the current schema definition of an asset to its previous state, on a continuous loop. Any delta — even a metadata-only change like a column reordering — gets surfaced.
Schema is the pillar that scales worst without lineage. A single upstream change can fire forty alerts across downstream tables, models, and dashboards. Each alert, in isolation, looks like a separate incident. Engineers investigate the same root cause from five different angles, and the ratio of alerts to actual root causes climbs into 40:1 territory.
The fix is structural: schema observability needs lineage as a peer pillar, not as a follow-up tool you open after the alert fires. Which brings us to the pillar that turns schema noise into schema signal.
Pillar 4 — Lineage
Lineage maps the dependency chain between assets — which tables feed which models, which models feed which dashboards, which dashboards feed which decisions. It is the pillar that connects everything else in the framework.
On its own, lineage is metadata. Combined with the other pillars, it becomes the difference between alert chaos and clustered clarity. A schema change on orders_raw produces one root-cause event in a lineage-aware system, not forty independent symptoms. A volume drop on payment_events produces an impact analysis — five downstream assets affected, three of them powering AI feature stores — rather than a single alert with no business context attached.
Lineage is also what makes root cause analysis tractable. Without it, an engineer investigating a wrong number on an executive dashboard has to open five tools, query metadata in three of them, and message two teams to reconstruct the causal chain. With it, the chain is already mapped before anyone gets paged. Research from Acceldata’s 2025 data observability survey put manual root cause analysis at 2 to 8 hours per incident; the same survey put lineage-aware automated RCA at under 10 minutes for the same class of incident.
The pillar deserves a separate note: lineage is the only pillar in the framework that becomes more valuable as the data estate grows. The other six pillars produce signals that scale linearly with the number of monitored assets. Lineage produces correlations, and correlations scale with the dependency graph — which is where the compounding value of a unified platform lives.
Pillar 5 — Distribution
Distribution observability monitors the statistical shape of the data inside the columns — not whether the data arrived, but whether it looks the way it should once it has. Null rates, value ranges, category mixes, mean and variance against historical baselines.
The signal is what catches the failures that pass every structural check. A pipeline runs on time. The volume is right. The schema is intact. But the amount column that normally has a median of $84 now has a median of $0.84 because an upstream system started reporting amounts in cents instead of dollars. The data is technically valid. It is also wrong by a factor of 100. Only a distribution check catches it.
Many observability sources use “quality” and “distribution” interchangeably for this pillar, and the substitution is mostly harmless. Distribution names the mechanism — statistical-shape detection. Quality names the outcome — whether the data is trustworthy enough to act on. Either word works; the underlying pillar is the same.
The distinction worth holding is the one between distribution observability and data quality management. Distribution sits inside the observability framework as a detection pillar. Data quality as a discipline covers a broader set of activities — defining what “correct” means, building enforcement rules, and managing remediation workflows. The relationship between the two is dealt with at length in the data observability vs. data quality discussion. Inside the seven-pillar framework, distribution is the signal layer that data quality builds on.
Pillar 6 — Pipeline (the DQLabs extension)
Pipeline observability is the first of the two pillars that the canonical five-pillar framework leaves out, and the reason it deserves separate pillar status is structural.
The five canonical pillars all observe the data. They watch what arrives, how much arrives, what shape it takes, where it came from, and what its values look like. They do not watch the system that moves the data. A pipeline can degrade in ways that none of the five canonical pillars surface: an Airflow DAG that completes successfully but takes four times longer than usual, a dbt run that passes all tests but produces a warning about source freshness on an upstream model, a streaming consumer that is silently falling behind on partition offsets.
These are not data anomalies. They are pipeline anomalies — and at enterprise scale, where a single data team owns hundreds of orchestrated workflows, they are the leading indicator of failures the data layer eventually surfaces hours later. Pipeline observability watches them directly: job health, latency, throughput, dependency lag, orchestrator state, transform-engine signals.
The AI-era justification for treating pipeline as a standalone pillar is straightforward. Enterprises are running fully orchestrated pipelines that feed AI consumers with no human in the loop — real-time Kafka queues, automated dbt model creation, lake-house loading, agentic AI ingestion. In those architectures, the pipeline is not a delivery mechanism the data layer can recover from after the fact. It is the only validation layer between the source and the model. If the pipeline silently degrades, the AI consumes whatever degraded output arrives.
Treating pipeline as a sixth pillar — peer to freshness, volume, schema, lineage, and distribution — is what closes that gap. The pipeline gets observed continuously, with the same rigor as the data flowing through it.
Pillar 7 — Cost (the DQLabs extension)
Cost observability is the seventh pillar, and the most counterintuitive of the seven, because cost has historically lived in a separate FinOps conversation rather than inside the observability framework.
That separation made sense in 2020. Cloud spend on data infrastructure was a back-office concern, reviewed monthly, owned by finance. In 2026, it is a near-real-time engineering signal. A Snowflake credit anomaly is often the first detectable sign that a logic bug has shipped to production: a query that scans 50TB instead of 50GB, a transform that re-processes the same partition every fifteen minutes, a backfill that loops without a termination condition. The cost spike precedes the data anomaly by hours.
The pillar tracks credit and compute consumption per pipeline, per warehouse, per user, against historical baselines. A 3× cost spike on a previously stable workload is an anomaly worth investigating immediately — usually before the affected stakeholder notices anything wrong with the data itself.
Cost observability also closes a feedback loop the other six pillars cannot. A unified-platform argument can be made on cleanliness, on context, on faster RCA. It can also be made on dollars. When the team that owns the data also sees the cost behavior of the platform that processes it, optimization decisions stop being a quarterly FinOps exercise and start being part of incident response.
Treating cost as a pillar — peer to the other six, watched continuously, alerted on with the same intelligence — is what turns cloud-native data engineering from economically opaque into economically defensible.

The seven pillars are necessary. They are not sufficient.
Seven pillars produce signals. Whether those signals become operational outcomes depends on what sits above them.
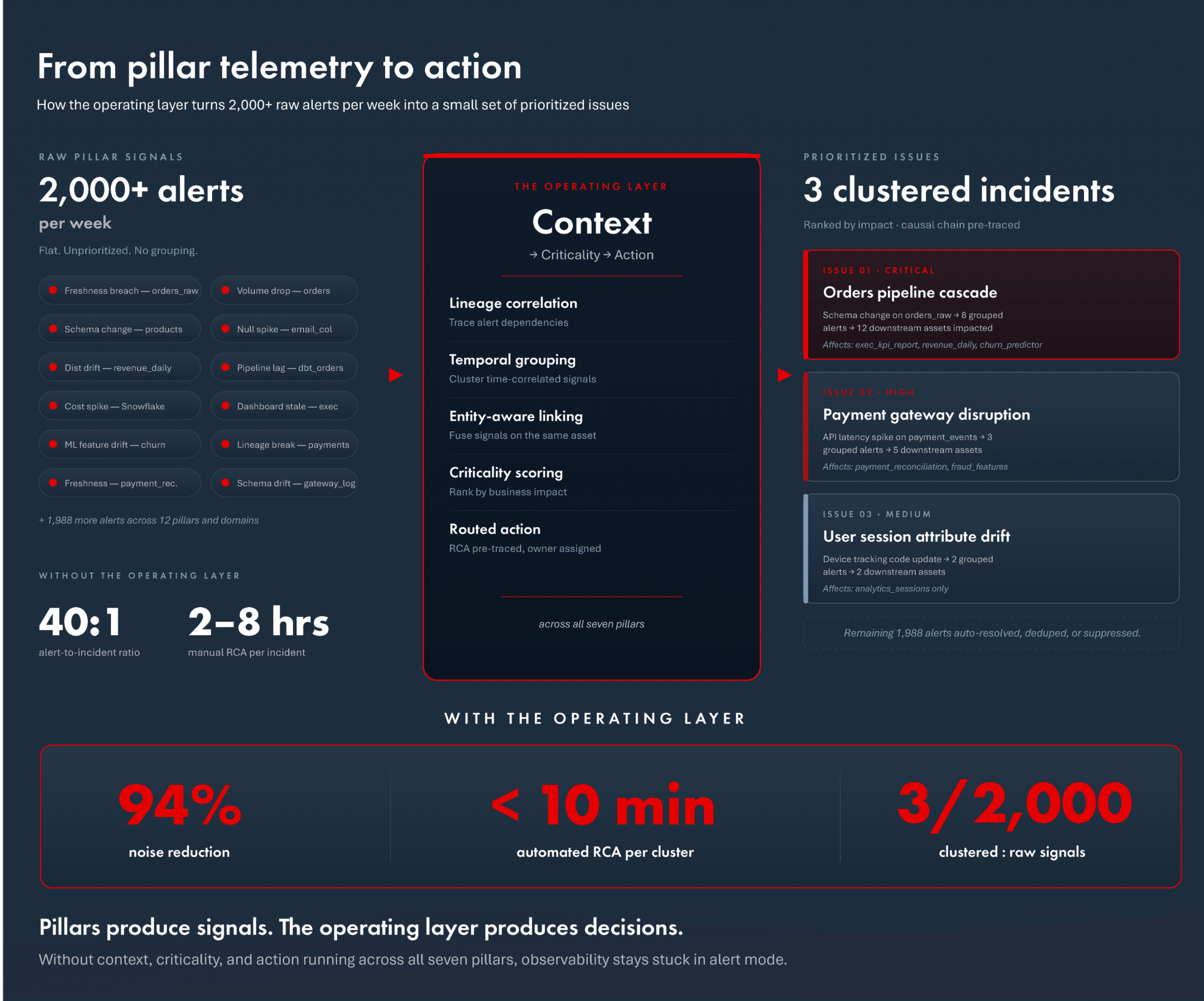
The pattern most enterprise data teams already know: an observability deployment that covers all seven pillars, monitoring every critical asset, generating 2,000 or more alerts per week, of which 5 to 10% require immediate action. The rest is noise — low-severity drift, expected weekend dips, cascading symptoms of a single upstream issue firing forty separate notifications across downstream tables, models, and dashboards. Research from a 2025 IEEE survey on platform-level data observability reported that 73% of organizations experienced outages caused by alerts that were suppressed or ignored. The problem is not detection. The problem is everything that happens between detection and action.
The fix is not a sixteenth or twentieth pillar. It is an operating layer that runs across the seven, turning raw telemetry into prioritized issues. Three capabilities define what that layer does.
The first is context. Metadata about ownership, business meaning, regulatory criticality, downstream consumption — captured from the catalog, from lineage, from usage patterns, from the dependency graph — gets joined to the pillar signals. The same volume drop on the same table reads differently depending on whether the table feeds a BCBS 239 regulatory report, a churn prediction model, or a developer’s experimental dashboard. Context is what makes that difference legible to the platform.
The second is criticality. With context attached, every issue can be scored by business impact: which downstream assets are affected, how many AI consumers depend on the data, what the consumer’s SLA looks like, whether the asset sits inside a regulated workflow. The output is a priority-ordered queue, not a flat list — and the schema change affecting the executive revenue dashboard arrives at the top, not at position 147.
The third is action. Prioritized issues route to the right teams with the right metadata, with suggested remediation paths surfaced alongside the alert. For known failure patterns, the action is automated. For unfamiliar patterns, the action is presented to a human with the full causal chain pre-traced. The operating layer is what turns a detect-and-alert architecture into a detect-explain-resolve architecture.
How the seven pillars compound when context drives action
The pillars are not seven independent observability lanes. Each pillar’s value is partial in isolation and substantial in correlation, and the correlation only happens when the operating layer above them shares context across all seven.
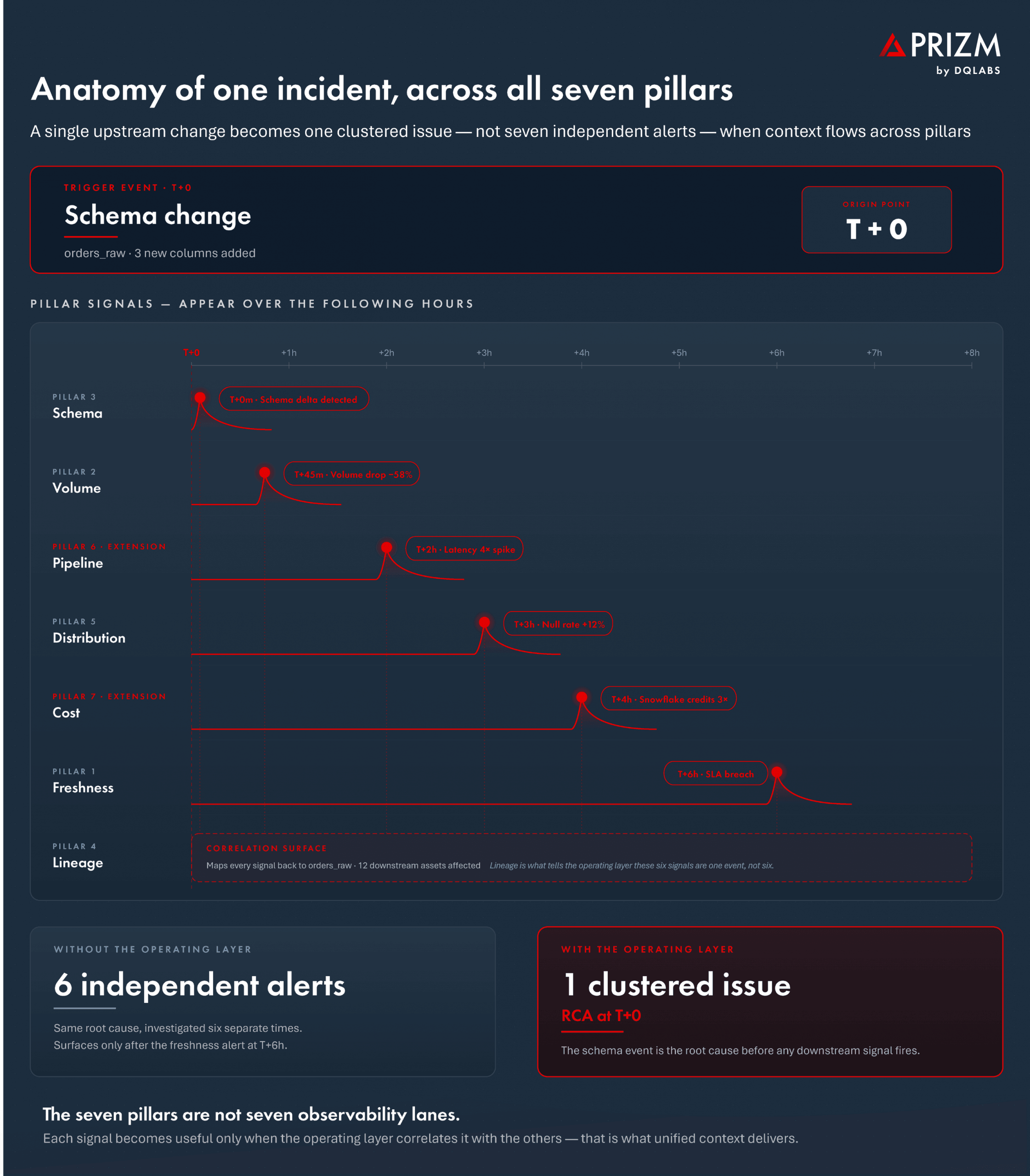
A volume anomaly on its own is a signal. A volume anomaly correlated with a freshness breach on the same asset, a schema change on the upstream source, and a 4× cost spike on the transform that joins them — that is one clustered incident with a clear origin, not four uncorrelated alerts. The same architectural principle that the unified-observability discussion treats as a point-solution gap shows up here at the framework level. Pillars that observe in isolation produce alerts. Pillars that share context produce issues.
This is also where the seven-pillar framework diverges most clearly from the five-pillar legacy. The five canonical pillars were designed for a world where each pillar was a separate detector and the human engineer was the correlation layer. The seven-pillar framework assumes the correlation layer is the platform — and that the platform’s job is not just to observe but to reason across what it observes. Pipeline and cost are not added pillars in a longer list. They are the two observability surfaces that, when correlated with the other five, give the operating layer enough signal to make criticality decisions a human alone could not make at enterprise scale.
How Prizm operationalizes the seven-pillar framework
Prizm by DQLabs treats the seven pillars as the detection layer and the context-criticality-action loop as the operating layer above them. The platform monitors freshness, volume, schema, lineage, and distribution as native first-class signals, alongside pipeline and cost as peer pillars. Every signal carries the metadata required for the operating layer to do its work — ownership, downstream consumers, business criticality, SLA, regulatory context — captured continuously from the data estate rather than configured rule-by-rule.
What the architecture produces is the behavior the rest of the framework is built for. A schema change on an upstream source surfaces as one clustered incident — with the affected downstream assets, the impacted dashboards, the AI consumers at risk, and the recommended remediation path — rather than as forty independent symptom alerts spread across the dependency graph. A cost anomaly on a transform shows up with the pipeline context attached, so the on-call engineer sees the logic bug, not just the spike. A distribution drift on a critical feature store routes immediately to the model owner with criticality scored against the model’s downstream business decisions, while a similar drift on a developer sandbox routes to the team backlog with severity dialed down.
The result is what the seven pillars promise but the canonical five cannot deliver alone: an observability platform that does not just report on the data estate but operates it. Detect, explain, resolve — across all seven pillars, with one shared context model behind them.
Frequently asked questions
What are the 5 pillars of data observability?
The five canonical pillars of data observability, as defined by Monte Carlo in 2020, are freshness, volume, schema, lineage, and distribution. Freshness tracks whether data arrives on schedule. Volume tracks row-count consistency. Schema tracks structural changes such as added or dropped columns. Lineage tracks upstream and downstream dependencies. Distribution tracks the statistical shape of the data — null rates, value ranges, category mixes. Some sources substitute “quality” for distribution; the underlying pillar is the same. Together, these five define what every modern data observability platform monitors at minimum.
What are the 7 pillars of data observability?
The seven pillars extend the canonical five — freshness, volume, schema, lineage, distribution — with two additional pillars that enterprise data teams need at scale. Pillar six is pipeline observability, which monitors the system that moves the data: job health, latency, throughput, orchestrator state. Pillar seven is cost observability, which monitors credit and compute consumption as a continuous signal rather than a monthly bill. The seven-pillar framework treats observability as covering the data, the system that moves the data, and the financial behavior of the platform together.
Why do pipeline and cost deserve to be separate pillars?
Pipeline and cost are separate pillars because they observe surfaces the five canonical pillars do not. The five canonical pillars observe the data itself — what arrives, how much, what shape, from where, and with what values. They do not observe the pipeline that moves the data, which can degrade silently in ways that none of the five surface. They also do not observe cost behavior, which in cloud-native environments precedes most data anomalies by hours. Treating pipeline and cost as pillars — peer to the canonical five, watched continuously, alerted on with the same intelligence — is what the AI-era enterprise data stack requires.
Is data observability the same as data monitoring?
Data observability and data monitoring are not the same. Monitoring tracks predefined metrics against fixed thresholds and tells you when something known has broken. Observability tracks the broader signal surface, learns baselines automatically, detects anomalies that no rule was written for, and connects signals across pillars to surface root causes rather than symptoms. The full distinction, including the SRE-rooted technical origin of the difference, is dealt with in the data observability vs. data monitoring discussion.
How do the pillars relate to data quality?
Data quality and the pillar framework are layered, not parallel. Distribution observability — pillar five — is the detection layer that surfaces statistical anomalies in the data itself. Data quality as a discipline builds on that detection layer with rule definition, enforcement workflows, and remediation. The seven-pillar framework defines what is observed. Data quality defines what to do about what is observed, on the specific dimension of correctness. The two work together inside a unified platform; the boundary between them is covered in the data observability vs. data quality discussion.