

Summarize and analyze this article with
Key Takeaways
Data observability in 2026 goes far beyond monitoring. It is a strategic discipline that ensures data reliability across pipelines, warehouses, and AI models. Organizations that adopt intelligent, context-aware observability reduce alert noise by up to 90%, cut mean-time-to-resolution significantly, and build the data trust foundation required for AI readiness. The shift from reactive alerting to autonomous, business-aligned data operations is no longer optional—it is the defining differentiator for data-mature enterprises.
Understanding Data Observability: Definition and Fundamentals
Data observability is an organization’s ability to fully understand the health, reliability, and behavior of data as it flows through complex systems. It extends the principles of application observability—monitoring, alerting, and tracing—to the data layer, giving data engineers and leaders visibility into what is happening with their data at every stage of its lifecycle.
At its core, data observability answers a deceptively simple question: Can I trust this data? It does so by continuously monitoring key dimensions of data health and providing the context needed to detect, explain, and resolve issues before they cascade into business impact.
The Five Pillars of Data Observability
The foundational framework for data observability rests on five interconnected pillars, each addressing a critical dimension of data health:
- Freshness: How up-to-date is your data? Freshness monitoring detects stale tables, delayed pipeline runs, and unexpected gaps in data arrival. In an era where AI models and real-time dashboards depend on timely data, even a few hours of staleness can lead to flawed decisions.
- Volume: Is the data arriving within expected size bounds? Anomalous spikes or drops in row counts, missing partitions, or unexpected duplicates all signal potential pipeline failures or source-system issues.
- Schema: Has the structure of your data changed unexpectedly? Schema drift—new columns, removed fields, type changes—is one of the most common causes of silent pipeline failures. Observability here catches what unit tests miss.
- Distribution: Are statistical properties of your data within normal ranges? Distribution monitoring identifies outliers, null-rate changes, and shifts in value patterns that indicate data quality degradation.
- Lineage: Where did this data come from, and what depends on it? End-to-end lineage traces data from source systems through transformations to consumption, providing the map needed for root cause analysis and impact assessment.
Beyond these five pillars, modern data observability in 2026 also encompasses pipeline monitoring, cost and compute tracking, and autonomous quality rule enforcement—creating a holistic view of the entire data ecosystem.
Why Data Observability Is a Strategic Imperative in 2026
The data landscape of 2026 looks fundamentally different from even two years ago. Three converging forces have elevated data observability from a nice-to-have engineering practice to a board-level strategic priority.
AI Has Changed Who (and What) Consumes Data
The most significant shift is that data consumers are no longer just humans. AI models, LLM-based agents, and automated decision systems now consume enterprise data directly—often without human review. When a stale table feeds a pricing model, or a schema change silently breaks an AI agent’s input pipeline, the consequences are immediate and costly: wrong recommendations, compliance failures, revenue leakage.
Today, 10–20% of enterprise data is curated by humans for decision-making. Industry projections suggest that 60–70% of enterprise data will need to be AI-ready within the next two to three years. This exponential expansion of data consumption makes automated, continuous observability essential—manual spot-checks and ad-hoc monitoring simply cannot scale.
Complexity Has Outpaced Traditional Monitoring
Modern data stacks involve dozens of interconnected tools: ingestion frameworks, transformation layers, orchestrators, warehouses, lakehouses, BI platforms, and ML feature stores. A single data asset might pass through fifteen transformations before reaching a dashboard. Traditional monitoring—checking if a job succeeded or a table updated—captures only a fraction of what can go wrong. Data observability provides the depth and breadth needed to monitor data itself, not just the infrastructure around it.
The Cost of Data Distrust Is Measurable
When data teams cannot trust their data, the downstream effects compound rapidly. Analysts waste hours manually validating reports. Data scientists retrain models on faulty inputs. Business leaders delay decisions. Gartner forecasts that 50% of organizations with distributed data architectures will adopt sophisticated observability platforms by end of 2026—up from less than 20% in 2024—reflecting the urgency of the moment.
The Scaling Challenge: When More Monitoring Creates More Problems
Here is the paradox that many data teams face in 2026: they invested in observability tooling, deployed automated monitors, and saw early wins in catching data issues faster. But as they scaled—more tables, more pipelines, more rules—things got worse, not better.
The Alert Fatigue Problem
A single dataset with 150 columns can generate between 900 and 1,200 automated monitoring rules. Multiply that across hundreds of datasets, and a data engineering team can face thousands of alerts per week. The result is alert fatigue—a state where the sheer volume of notifications makes it impossible to distinguish critical issues from noise.
Alert fatigue is not just an annoyance; it is a systemic failure mode. When engineers are overwhelmed by low-priority alerts, they inevitably miss the high-impact ones. Response times increase. Trust in the observability system itself erodes. Teams start ignoring alerts altogether, which defeats the entire purpose of monitoring.
The Root Cause: Lack of Context
The deeper issue behind alert fatigue is not too many alerts—it is too little context. Traditional observability tools treat every anomaly as an independent event. They detect that a freshness threshold was breached or a null rate spiked, but they cannot answer the questions that actually matter:
- Is this data asset business-critical, or is it a rarely used staging table?
- Is this alert related to the twenty other alerts that fired in the last hour?
- What downstream dashboards, models, or AI agents are affected?
- Does this require immediate action, or can it wait until the next business day?
Without context, every alert carries equal weight. Without prioritization, every issue demands the same response. The result is reactive firefighting instead of strategic data operations.

The Evolution of Data Observability: From Manual to Autonomous
Understanding where data observability is heading requires understanding where it has been. The maturity journey follows a clear progression, and most organizations in 2026 find themselves somewhere in the middle—aware of the need for something better but unsure what that looks like.
| Maturity Stage | Capabilities | Limitation |
| Manual Monitoring | Scheduled SQL checks, cron-job validators, manual data profiling | Reactive, unscalable, no lineage visibility |
| Rule-Based Alerting | Threshold-based alerts, schema change detection, basic freshness checks | High noise, no prioritization, every alert treated equally |
| ML-Driven Anomaly Detection | Automated baselines, statistical anomaly detection, pattern learning | Better detection but still no business context; alert volume remains high |
| Context-Aware Observability | Alert clustering, lineage-based impact analysis, criticality scoring, prioritized remediation | Emerging standard; requires deep metadata integration (offered by platforms such as Prizm by DQLabs) |
| Autonomous Data Operations | Self-driving detection, explanation, and resolution; AI-powered stewardship with human oversight | The frontier: platforms that act on your behalf, guided by business context (such as Prizm by DQLabs) |
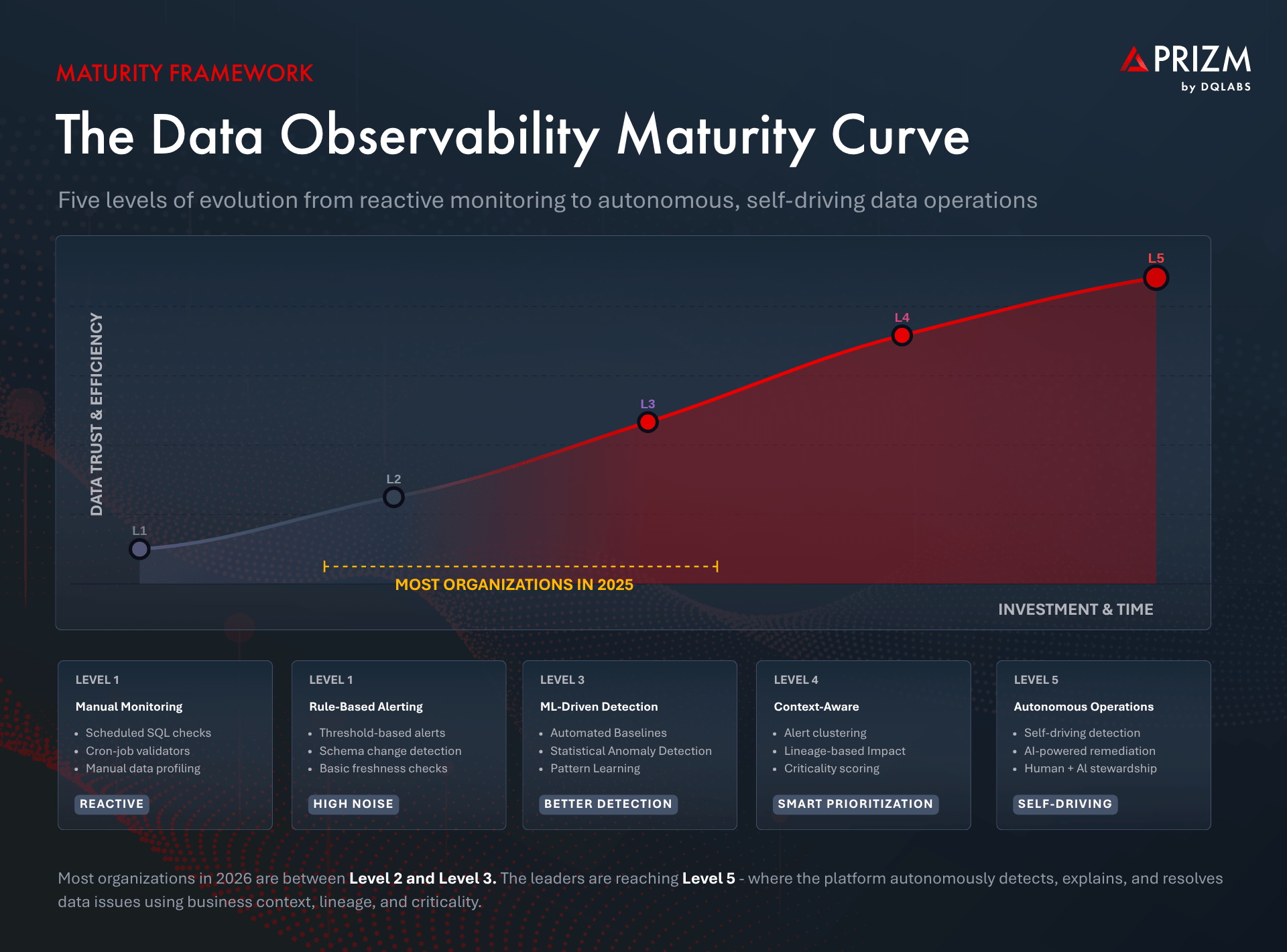
The critical leap is from Level 3 to Level 4—where observability stops being about detecting more anomalies and starts being about understanding which anomalies matter. This is the point where context transforms raw signals into actionable intelligence.
How Context-Aware Observability Solves the Scaling Challenge
Context-aware observability represents a fundamental architectural shift. Instead of treating alerts as isolated events, it connects them to the broader data ecosystem—lineage, business usage, criticality, ownership, and downstream impact—to deliver prioritized, actionable insights.
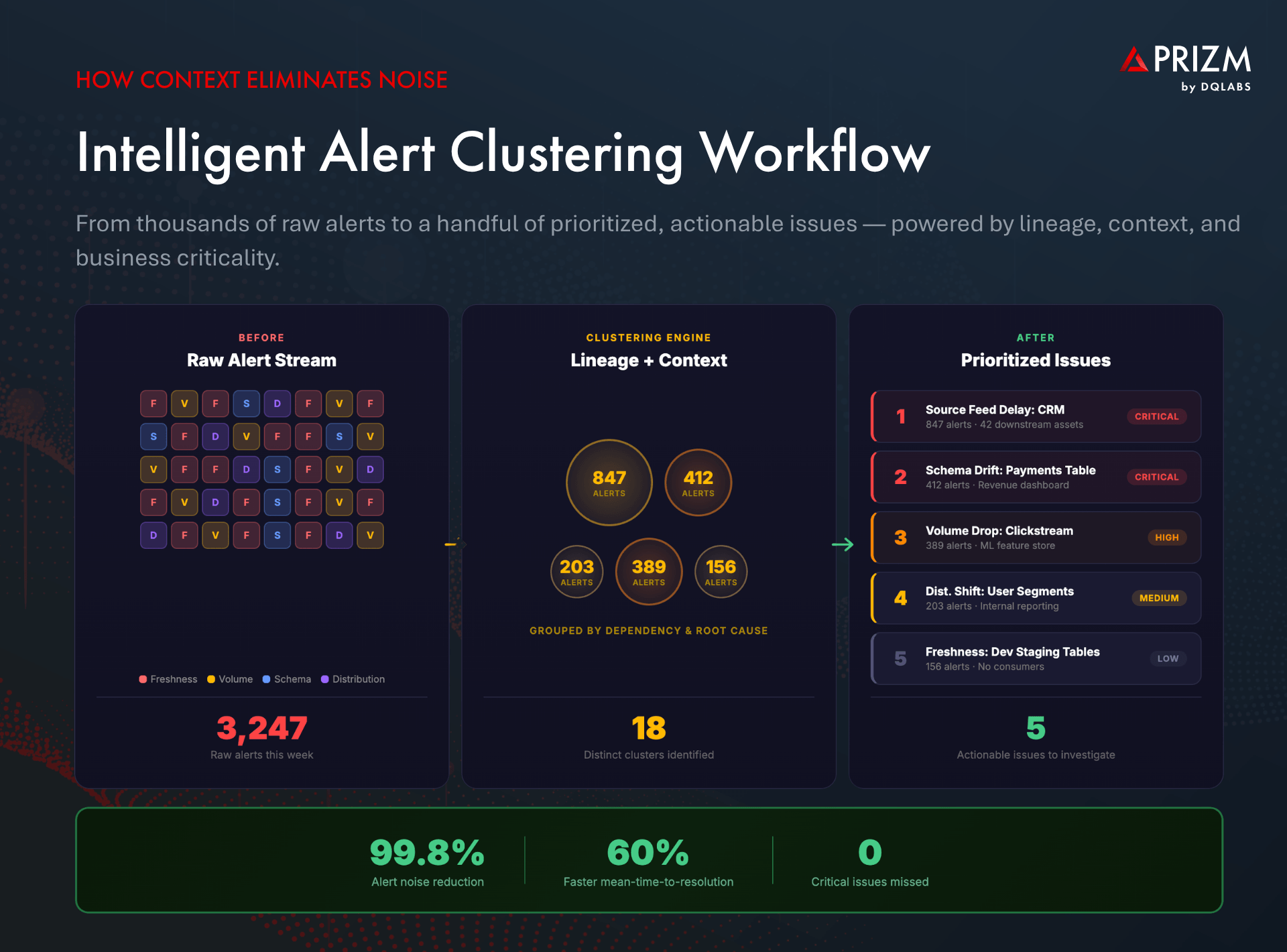
Alert Clustering: From Thousands of Alerts to a Handful of Issues
When an upstream source system fails, it does not generate one alert. It generates dozens—or hundreds—as every downstream table, view, and dashboard that depends on that source detects its own freshness or volume anomaly. Without clustering, each of these alerts appears as an independent problem, overwhelming the team.
Intelligent alert clustering groups related alerts based on data lineage and temporal correlation. A platform that understands the dependency graph can automatically trace hundreds of downstream alerts back to a single root cause—a delayed source table, a schema change in a bronze layer, or a failed transformation job. Instead of investigating fifty alerts, the data engineer sees one cluster with a clear root-cause indicator.
Criticality Scoring: Not All Data Is Created Equal
A key insight that separates mature observability from basic monitoring is that data assets have vastly different business importance. A staging table used by one internal script does not deserve the same alerting urgency as a fact table that feeds executive dashboards, revenue calculations, and customer-facing AI models.
Context-aware platforms automatically assess criticality by analyzing usage patterns (who and what queries this data), lineage position (how many downstream assets depend on it), business domain tagging (is this tied to revenue, compliance, or customer experience), and freshness sensitivity (how quickly does staleness create impact). This criticality score then determines the urgency of alerts, the depth of profiling, and the priority of remediation—all automatically.
Impact Analysis: Understanding the Blast Radius
When a data issue is detected, the first question a data engineer asks is: What is affected? Context-aware observability provides the answer through end-to-end visual lineage that maps every upstream source and downstream consumer. Engineers can immediately see whether an anomaly in a bronze-layer table will propagate to a critical gold-layer fact table, which dashboards will show incorrect numbers, and which AI models might produce unreliable outputs.
This “blast radius” analysis turns data incident response from guesswork into precision. It also enables proactive communication—data stewards and consumers can be notified about potential impact before they discover it themselves.
The Next Frontier: Autonomous, Self-Driving Data Observability
Context-aware observability is a significant advancement, but the trajectory does not stop there. The most forward-looking data organizations in 2026 are moving toward autonomous data observability—platforms that do not just detect and explain issues but actively resolve them, continuously learn from outcomes, and operate with minimal human intervention.
The Self-Driving Analogy
Think of the evolution of data observability like the evolution of driving. Manual monitoring is like driving a stick shift—full control, full effort, and full attention required at all times. Rule-based alerting is automatic transmission—some burden is lifted, but you are still driving. ML-driven detection adds cruise control—the system maintains speed, but you handle the steering. Context-aware observability is like advanced driver-assistance—the system warns you, adjusts course, and handles routine situations.
Autonomous data observability is the self-driving car. The platform ingests metadata from your sources, transforms it into actionable context, uses that context to determine criticality and prioritization, and then takes action—triggering remediation workflows, enforcing data quality policies, and notifying the right stakeholders—all governed by human-defined guardrails and AI stewardship.
What Autonomous Observability Looks Like in Practice
An AI-native autonomous observability platform operates through a continuous cycle:
- Metadata becomes context. The platform ingests technical metadata (schemas, row counts, freshness timestamps) and enriches it with business context (ownership, domain classification, usage patterns, downstream dependencies). Raw metadata alone is noise. Context makes it meaningful.
- Context drives prioritization. Every data asset receives a criticality score based on its lineage position, consumption patterns, and business domain. Critical assets get deeper profiling, more sensitive alerting thresholds, and faster response workflows.
- Criticality determines actions. The platform autonomously decides what to do based on the severity and business impact of each issue. High-criticality freshness failures trigger immediate remediation workflows. Low-criticality schema changes are logged and surfaced in weekly reviews.
- AI supports every action. From generating plain-language explanations of anomalies to recommending quality rules, from auto-documenting data assets to providing guided remediation steps, AI is embedded in every interaction between the platform, data engineers, and data consumers.
This cycle—detect, explain, resolve, learn—runs continuously, creating an autonomous trust layer between your data sources and the business and AI consumers that depend on reliable data.
Human + AI Stewardship
Autonomous does not mean unsupervised. The most effective approach combines AI-driven automation with human oversight through graduated autonomy levels. Some actions—like profiling a new data asset or clustering related alerts—run fully autonomously. Others—like applying a new data quality rule to a critical production table—are AI-recommended but human-approved. The platform learns from every human decision, continuously improving its autonomous capabilities over time.
Real-World Use Cases: Data Observability in Action
For Data Engineers: Zero Alert Fatigue
A retail data engineering team managing 500+ data assets across Snowflake was drowning in over 3,000 alerts per week. After deploying context-aware alert clustering, those alerts collapsed into fewer than 30 prioritized clusters, each with a clear root-cause indicator and lineage-traced blast radius. Engineers shifted from reactive firefighting to proactive resolution, cutting mean-time-to-resolution by more than 60%.
For Data Stewards: Executable Governance
A financial services organization struggled to enforce data quality policies that existed only in documentation. With autonomous observability, business rules are automatically recommended based on data profiling, enforced through continuous monitoring, and tracked with ownership and SLA workflows. Governance became measurable and executable—not advisory.
For Data Leaders: AI-Ready Data Confidence
A healthcare analytics team needed assurance that the data feeding their AI diagnostic models was reliable and current. End-to-end lineage with context-driven health indicators gave them continuous visibility into freshness, quality, and trust scores for every critical data asset—enabling confident AI deployment and faster regulatory compliance.
For Data Consumers: Trust Without Verification
Analysts and data scientists previously spent the first 30 minutes of every analysis manually verifying whether the data was up-to-date and accurate. Conversational AI interfaces now allow them to simply ask the platform about data health, freshness trends, and quality scores—eliminating manual validation and restoring trust in the data layer.
A Practical Framework for Implementing Next-Gen Data Observability
For organizations ready to evolve their observability practice, the following framework provides a structured approach:
- Step 1: Connect and Ingest. Integrate with your existing data sources, pipelines, catalogs, and BI tools. The goal is comprehensive metadata ingestion—not stack replacement. The best platforms work with your existing infrastructure, not against it.
- Step 2: Build Context. Enrich technical metadata with business context. Classify data assets by domain, assign ownership, map lineage, and establish criticality scores. This is the foundation everything else builds on.
- Step 3: Enable Intelligent Alerting. Deploy alert clustering, root cause analysis, and criticality-based prioritization. The objective is to reduce alert noise by 80–90% while ensuring zero critical issues are missed.
- Step 4: Automate Actions. Implement autonomous remediation for well-understood issue patterns. Start with lower-risk automations (auto-profiling, documentation generation) and progressively expand to higher-impact actions (quality rule enforcement, pipeline restart triggers).
- Step 5: Measure and Learn. Track operational metrics: mean-time-to-detection, mean-time-to-resolution, alert-to-issue ratio, data trust scores. Use these metrics to continuously tune the system and demonstrate ROI to leadership.
The Future of Data Observability: What Comes Next
Looking at 2026, several trends are shaping the next chapter of data observability:
- Observability for AI Agents. As agentic AI becomes mainstream, observability will extend to monitoring the data consumed and produced by AI agents in real-time—ensuring that autonomous AI decisions are grounded in trustworthy data.
- Cost-Aware Operations. Data engineering workloads are among the most expensive in modern organizations. Observability platforms will increasingly integrate cost and compute tracking, enabling teams to optimize not just data quality but data economics.
- Data Contracts at Scale. Observability will become the enforcement layer for data contracts—formalized agreements between data producers and consumers about schema, freshness, quality, and availability expectations.
- Proactive, Business-Aligned Reliability. The ultimate vision is a data ecosystem where reliability is not an afterthought but an embedded, continuous, and business-aligned practice—where the platform understands organizational priorities and autonomously ensures the most critical data is always the most trusted.
Frequently Asked Questions About Data Observability
What is data observability and why does it matter?
Data observability is the ability to understand the health and reliability of data across your entire ecosystem. It matters because unreliable data leads to broken dashboards, failed AI models, compliance risks, and eroded stakeholder trust. In 2026, where AI models and automated systems consume data directly, observability is the foundation of data-driven operations.
What are the five pillars of data observability?
The five pillars are freshness (is data current), volume (is data complete), schema (is the structure stable), distribution (are statistical patterns normal), and lineage (where did data come from and what depends on it). Together, they provide comprehensive coverage of data health.
How is data observability different from data monitoring?
Data monitoring checks whether systems and pipelines are running. Data observability goes deeper—it examines the data itself to understand quality, freshness, schema stability, and behavioral patterns. Monitoring tells you a job finished; observability tells you whether the data it produced is trustworthy.
What is alert fatigue in data engineering?
Alert fatigue occurs when data teams receive so many notifications that they cannot distinguish critical issues from noise. It typically happens when observability tools scale monitoring rules without adding context or prioritization, leading engineers to ignore or deprioritize alerts and ultimately miss high-impact data failures.
What is autonomous data observability?
Autonomous data observability refers to AI-native platforms like Prizm by DQLabs that go beyond detection to actively explain and resolve data issues. These platforms use context—lineage, usage patterns, business criticality—to prioritize what matters, cluster related alerts, and take corrective actions with appropriate human oversight.
How does alert clustering reduce data engineering workload?
Alert clustering uses data lineage and temporal correlation to group hundreds of related alerts into a single incident cluster with a common root cause. Instead of investigating each alert individually, engineers address the root cause once, resolving all downstream symptoms simultaneously. This can reduce alert investigation time by 80–90%.
What should data leaders look for in a 2026 observability platform?
Key capabilities to evaluate include AI-native architecture, context-driven alert clustering and prioritization, end-to-end visual lineage with impact analysis, autonomous remediation with human oversight, adaptive profiling based on criticality, conversational AI interfaces for all stakeholders, and seamless integration with existing data infrastructure.