

Summarize and analyze this article with
The Data Catalog Market Is Changing Again. Here Is How.
The data catalog category has reinvented itself more than any other layer of the enterprise data stack. Each generation arrived with confidence that it had finally solved discovery, governance, and trust. Each was displaced within a few years, not because the previous generation was wrong, but because the demand on the catalog kept escalating. In 2026, the category is mid-shift again, and the new center of gravity is not faster discovery or richer metadata. It is validated context. The catalog is becoming the layer that does not just describe data, but vouches for the meaning, ownership, quality, and trust state of every asset, in real time, for both humans and AI agents.
This article walks through the five generations of the catalog, what is forcing the current shift, and what the validated context era will demand from platforms, programs, and the data leaders who fund them.
Five Generations in Less Than a Decade
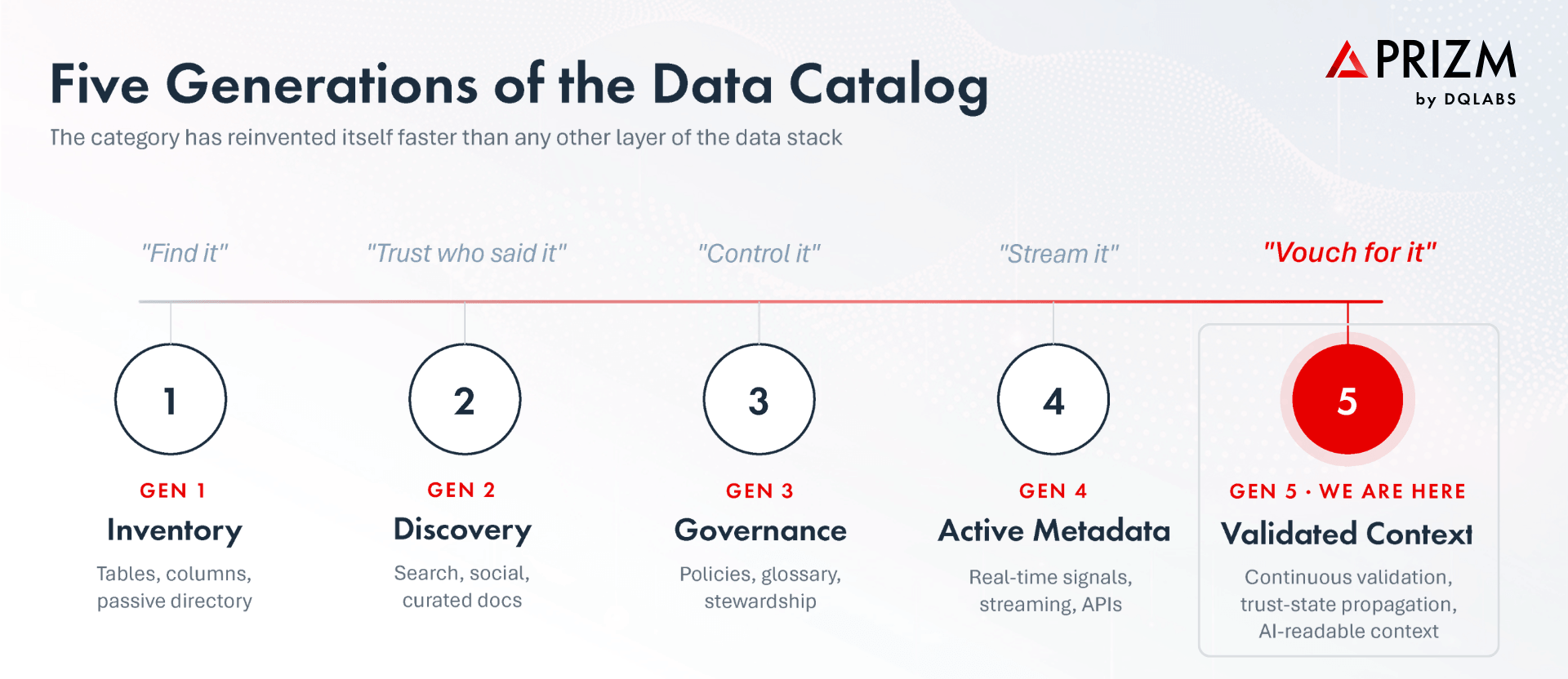
Generation One: Inventory Catalogs
The first wave of data catalogs treated metadata as a directory problem. The job was to crawl databases and produce a centralized inventory of tables, columns, and schemas so that analysts could find what existed. These were useful but passive. They sat outside the operational workflow, were maintained on a quarterly cadence at best, and grew stale almost immediately. Their value proposition was, essentially, a more searchable list.
Generation Two: Discovery Catalogs
The second wave layered search, social signals, and lightweight collaboration on top of the inventory. Ratings, comments, and curated documentation made it possible for analysts to find not just data but data that someone else thought was usable. Discovery catalogs improved adoption meaningfully, but their model still assumed that humans were the primary consumers and that data quality was someone else’s problem.
Generation Three: Governance Catalogs
The third wave brought policies, glossaries, ownership, classification, and data stewardship into the same surface. Regulatory pressure, particularly around privacy and risk reporting, made it untenable to keep governance in a separate set of tools. Governance catalogs added durability to the category but also brought weight: more workflows, more committees, more administrative overhead. Many programs stalled here because the catalog felt like a compliance artifact rather than an operating system.
Generation Four: Active Metadata Platforms
The fourth wave was the active metadata era. The thesis, articulated most clearly by Gartner around 2020, was that metadata should not sit in a passive store but should flow continuously through the stack as signals that other systems could act on. Lineage events, query logs, usage signals, and quality scores started moving in real time. Catalogs grew APIs and event streams. Integration with observability and quality tools became the default. This wave produced platforms that were vastly more useful than their predecessors and that genuinely operated at scale.
Generation Five: Validated Context Platforms
The current shift is the move from active metadata to validated context. The catalog is no longer just a place where metadata lives or even flows. It is the layer that constructs and continually validates the meaning of every data asset, in business terms, for the specific consumer asking, with trust signals that humans and AI agents can act on at decision time. The catalog is becoming a context layer with quality and observability fused into it.
The reason the shift is happening now is not theoretical. It is operational. Three forces have converged.
What Is Forcing the Shift
The first force is the AI workload. Generative and agentic systems consume context continuously and at machine scale. They do not need a static description of what a table is; they need to know what the table means in business terms, who owns it, how fresh it is, what its trust score is, and whether the definition the model used yesterday is still current. The active metadata generation produced useful raw materials. It did not produce a layer the AI could safely trust without additional validation.
The second force is the scale of enterprise data estates. Most large organizations now manage tens or hundreds of thousands of tables, models, and reports across cloud warehouses, lakehouses, transformation layers, BI tools, and operational systems. Cataloging at this scale without autonomous coverage is impossible. The catalog has to be intelligent, not just searchable.
The third force is the lost trust problem. Active metadata catalogs in many enterprises now contain so much information that consumers cannot tell which parts to trust. Two definitions of the same metric, three lineage variants for the same table, four owners with different mandates, all coexist in the catalog and consumers learn to ignore the metadata that should help them. Validated context is the response. It is the discipline of asserting, for every consumer at every decision, what is current, what is complete, and what is reliable, with the evidence and audit trail to back it up.
What Validated Context Actually Looks Like
Validated context is not a feature. It is a posture across the platform. Three properties separate it from the active metadata generation.
It is composite. Validated context combines semantic meaning (what does this asset mean in business terms), operational signals (freshness, schema, volume), quality signals (accuracy, completeness, distribution, segment performance), usage signals (who consumes it, how often, in what surfaces), governance state (ownership, classification, policy alignment), and trust state (an aggregated score with drillable components). The catalog is no longer one of these things. It is all of them, fused into a single intelligence layer.
It is continuously evaluated. Validated context is not a one-time enrichment exercise. The layer continuously reassesses freshness, accuracy, completeness, lineage stability, and segment-level coverage, and it propagates the resulting trust signals through lineage to dependent assets. When a critical reference table degrades, every downstream asset whose context depended on it sees its trust state adjust automatically.
It is exposed where decisions happen. Validated context belongs in the surfaces where humans and AI agents already work: BI tools, conversational interfaces, AI copilots, MCP-enabled agents, and data product pages. A trust score that lives in a portal nobody visits is not validated context. A trust score that surfaces in Claude, Microsoft Copilot, Tableau, and Sigma at decision time is.
What This Means for Buyers in 2026
Buyers entering the catalog market in 2026 face a different selection problem than buyers in 2022. The questions are no longer about coverage of source systems and breadth of lineage. They are about whether the platform genuinely operates as a validated context layer, whether it makes the leap from describing data to vouching for it, and whether it integrates cleanly with observability and quality so context stays fresh and trusted.
Several questions are now decisive in selection conversations. Does the platform validate context continuously, not just on ingestion? Does it produce trust signals at the asset, domain, and product levels, with drillable components? Does it integrate observability and quality signals natively, or treat them as external feeds to be ingested separately? Does it expose context to AI agents via MCP or comparable protocols, so context is readable at decision time and not only in a portal? Does it scale across the long tail of an enterprise data estate, with criticality-driven prioritization that focuses validation effort where it matters most?
Answers to those questions distinguish the platforms that have made the shift to validated context from the platforms that are still operating as active metadata stores with marketing language refreshed.
Where Prizm Fits in This Shift
Prizm by DQLabs is one of the platforms built around this shift from the architecture up. DQLabs publicly positions Prizm as an AI-native platform where data observability, data quality, and context work together as one system, and that integration is what produces validated context rather than yet another metadata stream.
Prizm operates the context layer at three connected levels. It captures context by aggregating technical, operational, business, governance, and usage metadata across the connected estate. It operationalizes context by exposing it in conversational interfaces, in BI surfaces, and via MCP for external AI tools such as Claude and Microsoft Copilot. And it validates context continuously by linking the same surface to quality metric results, observability signals, lineage stability, stewardship activity, and outcome telemetry, so the catalog answers not only “what is this asset” but also “how good, current, complete, and reliable is the context for this asset right now.”
This validation posture is the difference. Most enterprise catalogs can describe a table; far fewer can certify that the description is still accurate today, that the lineage has not silently broken, that the freshness SLA is intact, and that the consuming AI agent should treat the context as trustworthy at this moment. That is the operating model the validated context era requires, and that is the model Prizm was designed around.
Implications for Data Leaders
For data leaders planning catalog investment in 2026, the strategic implications are clear.
First, the catalog is no longer an isolated investment. It belongs in the same architectural conversation as observability and data quality, because validated context only emerges when the three layers operate as one system. Buying a catalog without a coherent answer for how observability and quality feed into it produces an active metadata store, not a context layer.
Second, the AI program depends on this layer. Agentic systems will scale only as fast as the context that feeds them can be trusted. Programs that treat context validation as a parallel workstream rather than a precondition for AI deployment will continue to see initiatives stall at trust gates.
Third, the catalog evaluation criteria need to be rewritten. Connector count, glossary depth, and lineage breadth still matter, but they are necessary, not sufficient. The decisive criteria are context validation depth, integration of observability and quality signals, AI surface exposure, and stewardship posture for autonomous operation in regulated environments.
The Path Forward
The data catalog category has been the most reinvented layer in the enterprise data stack, and the current reinvention is the one that matters most. The shift from inventory to discovery improved adoption. The shift from discovery to governance improved compliance. The shift from governance to active metadata improved operational visibility. The shift from active metadata to validated context is the one that finally turns the catalog into the trust layer the enterprise needs to scale AI, satisfy regulators, and operate confidently at the size of modern data estates.
The platforms that win the next phase of this category are the ones that absorb this shift in architecture and operating model, not the ones that bolt validation language onto an active metadata product. Prizm by DQLabs is one of the clearer examples of what a validated context platform looks like when it is built deliberately. The buyers who recognize the shift and select against it will be the ones whose AI programs accelerate over the next eighteen months, while peers continue to investigate why their copilots are not deployed.
Frequently Asked Questions
Why is the data catalog market changing again in 2026?
Three forces are converging: AI workloads that consume context continuously, enterprise data estates that have grown beyond the scale of manual catalog maintenance, and an erosion of trust caused by active metadata catalogs accumulating too much unverified information. The category is shifting to validated context platforms in response.
What is the difference between active metadata and validated context?
Active metadata flows signals continuously across the stack but does not assert which parts are current, correct, or reliable. Validated context goes further. It continuously evaluates freshness, accuracy, completeness, lineage stability, and trust state, and exposes the resulting signals where humans and AI agents make decisions.
Why does AI need validated context specifically?
AI agents act on context at machine scale and fail silently when context is stale, ambiguous, or contradicted by upstream changes. Validated context is the layer that gives agents a defensible signal they can use to decide whether to act, defer, or escalate.
How does Prizm by DQLabs fit the validated context category?
Prizm is built as an AI-native platform where data observability, data quality, and context work together as one system. It captures context across the connected estate, exposes it through conversational, BI, and MCP-driven surfaces, and validates it continuously using quality and observability signals so the catalog can vouch for how good, current, complete, and reliable the context is at any moment.
What should buyers prioritize when evaluating catalogs in 2026?
Continuous context validation, native integration of quality and observability signals, exposure of context to AI agents via MCP or comparable protocols, criticality-driven coverage at enterprise scale, and stewardship posture that allows autonomous operation in regulated environments.
Is the validated context era replacing data catalogs or extending them?
It is the next generation of the data catalog category. The catalog is not going away. It is becoming a context layer with observability and quality fused into it, and the platforms that lead the next phase will be the ones that operate at that level of integration rather than as standalone metadata products.