
Summarize and analyze this article with
The enterprise data stack has never been more capable—and rarely has it felt more fragile.
Teams have modern warehouses and lakehouses, streaming pipelines, metrics layers, and dashboards everywhere. Yet a familiar pattern persists: data breaks silently, confidence drops quickly, and resolution takes too long. Engineers are flooded with alerts that lack context. Stewards are expected to be accountable without having the authority to enforce standards. Business users don’t know what to trust, so they validate manually—or stop trusting entirely.
At the same time, the stakes have changed.
AI has moved from experimentation to real operational usage, and it’s expanding who interacts with data. More non-technical users are building with data. More automated systems are consuming data. And as AI becomes embedded into daily workflows, “good enough” data is no longer good enough—because AI amplifies both reliability and risk.
This is the moment a new category boundary becomes clear: it’s not sufficient to monitor data, or to run quality checks, or to document meaning in a catalog. In the AI era, trust must be operational.
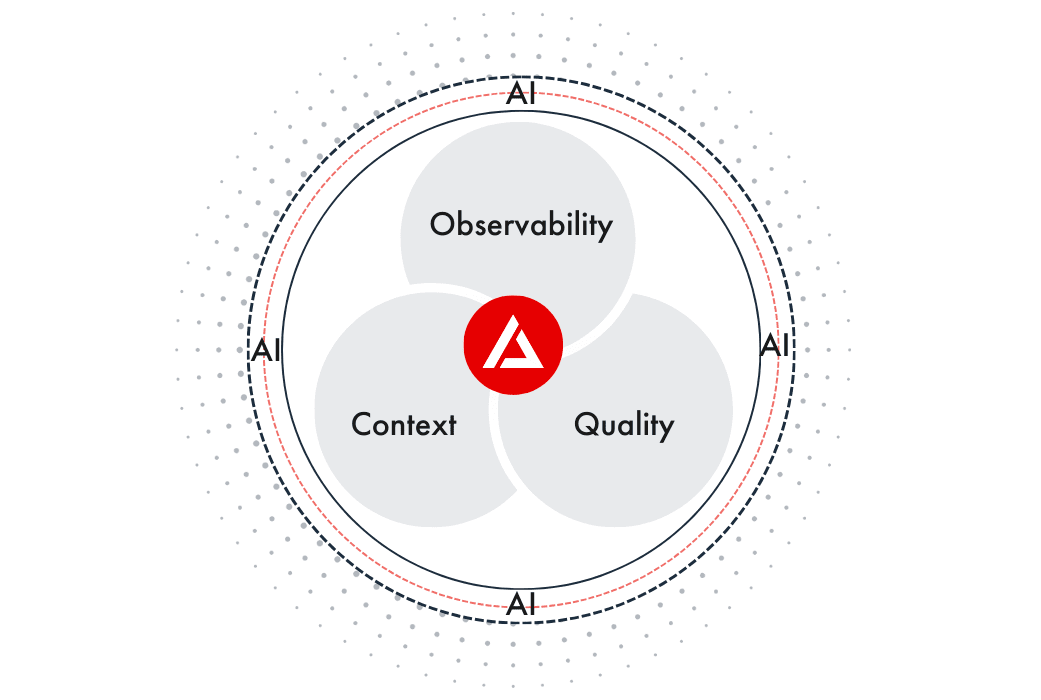
DQLabs has introduced Prizm—an AI native platform that unifies data observability, data quality, and context into a single operational layer for AI-ready data.
The market problem: fragmented tools, reactive operations
Most organizations have invested in solutions that solve parts of the data trust problem:
- Observability tools that detect pipeline anomalies and send alerts
- Data quality tools that validate fields and tables against rules
- Catalogs and governance programs that define ownership and standards
- Ticketing and incident processes that coordinate response
Each of these matters. But in practice, they often operate as parallel systems.
The result is fragmentation at the worst possible point: when something breaks and the business needs an answer. Data teams are left stitching together signals across tools, correlating symptoms manually, tracing lineage by hand, and debating whether a failure is critical or ignorable. Resolution becomes a human workflow held together by tribal knowledge.
That model does not scale—especially when AI accelerates consumption and raises the cost of error.
The market shift: from monitoring to operations
Observability made an important promise: see problems earlier. Data quality made another: ensure correctness and consistency. But both are incomplete if they stop at detection.
In the AI era, trust must extend through a closed loop:
- Understand what the data is and why it matters
- Measure health continuously as systems change
- Prioritize what matters most based on impact
- Drive action with clear ownership and control
This is the shift from “tools that report” to “systems that operate.”
It also changes what “AI native” really means.
What AI native means
Many platforms are adding AI features: summarizing incidents, generating rules, or answering questions in chat. Helpful—but often bolted onto an operating model that hasn’t changed. Alerts still arrive unprioritized. Ownership is still ambiguous. Remediation is still manual. Teams still spend time interpreting what the system already knows.
Prizm is built differently. It is AI native because AI is embedded in the core control plane—how context is gathered, how signals are interpreted, how priorities are set, and how action is orchestrated.
Prizm is designed to:
- Learn continuously from metadata, lineage, usage, and outcomes
- Connect observability signals to quality signals and business meaning
- Reduce noise by clustering and prioritizing what’s truly impactful
- Drive resolution—not just detection—through controlled automation
Why “context” is the missing third pillar
Data observability tells you something happened. Data quality tells you something is wrong. But neither reliably tells you:
- What this data means in the business
- Which downstream assets and KPIs are impacted
- Who owns the outcome
- What action is appropriate—and safe—right now
That is context. Context is what turns raw signals into decisions. It is also what makes automation useful. The more an enterprise wants systems to act autonomously, the more it must encode meaning, ownership, and policy into the operational layer—so action is aligned to business intent. Prizm treats context as a first-class operational input, not an afterthought.
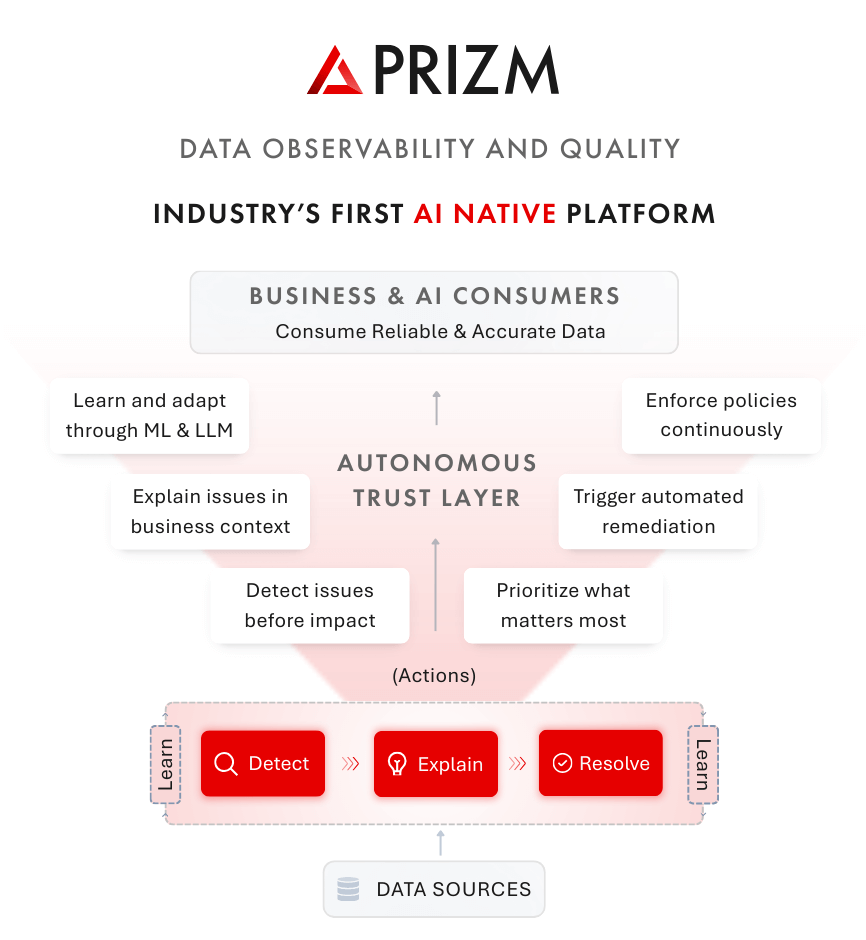
How Prizm works (conceptual view)
Prizm operates as a single control plane that continuously runs four steps—at enterprise scale:
Understand & learn
Prizm builds context across technical metadata, lineage, usage patterns, operational signals, and business meaning. This creates a living map of what data is, where it flows, who relies on it, and why it matters.
Evaluate trust (Detect)
Prizm continuously measures data health through observability and quality signals—freshness, volume shifts, schema changes, distribution drift, rule violations, and more. Trustworthiness is evaluated in real time, not in periodic audits.
Prioritize what matters (Explain)
Not all data is equally important. Prizm uses lineage and usage to understand downstream impact, then applies criticality and business context to prioritize. This reduces noise and focuses attention on what actually affects decisions and AI outcomes.
Drive action—with control (Resolve)
When issues occur, Prizm clusters related signals, explains likely root causes, identifies impacted assets, and orchestrates remediation. Some actions can be automated. Others require human oversight. Prizm supports this through clear operational modes that match the enterprise’s risk posture.
Autonomous data operations, governed by the enterprise
“Self-driving” does not mean “uncontrolled.” In the enterprise, automation must be aligned to policy, auditability, and accountability.
Prizm is designed to operate across modes based on need:
- Fully autonomous execution when risk is low and confidence is high
- AI-assisted workflows where humans approve decisions and actions
- Human-driven workflows where policy or regulation requires manual control
This allows organizations to introduce autonomy without sacrificing governance.
What makes Prizm different from traditional approaches
Prizm is not just “data quality plus observability.” The differentiation is the operating model.
Unified operational layer
Instead of treating observability, quality, and context as separate tool domains, Prizm unifies them into a single system of understanding and action—so teams don’t have to connect the dots manually.
AI at the core
Prizm is designed with AI embedded in the decision loop: learning context, interpreting signals, prioritizing impact, and orchestrating next steps—rather than adding AI as a UI feature.
Beyond detection, take actions autonomously
Prizm reduces mean time to resolution by clustering signal noise into actionable incidents, aligning them to ownership, and driving remediation through workflows and controlled automation.
Outcomes that matter to data leaders
For data leaders, the value is straightforward:
- Less time spent reacting to noise
- Faster resolution of high-impact incidents
- Clear ownership and accountability across domains
- More confidence in analytics and AI outputs
- A scalable path to AI-ready data without scaling headcount linearly
The vision: autonomous data trust layer for the enterprises
The next wave of enterprise systems will not just analyze—they will act. As agentic AI becomes more common, the enterprise will need a trust layer that can operate continuously, make prioritization decisions with business context, and drive controlled action.
Prizm is built for that future: a platform where data observability, data quality, and context work as one system—turning trust from a manual, reactive process into autonomous operations governed by the enterprise.
This is what AI-ready data should look like: continuously understood, continuously evaluated, and continuously operated—so teams can move faster with confidence.