

Summarize and analyze this article with
Data observability and data quality are not the same discipline. Quality defines the standard the business needs data to meet – accurate, complete, timely, valid, consistent, unique. Observability is the live enforcement layer that detects when the standard has been violated. The teams winning at AI in 2026 run them as one operating model on one platform.
The operational gap most data programs share
A team that has built comprehensive observability coverage finds, paradoxically, that alert volume keeps growing while signal-to-noise gets worse. High-impact issues continue to slip through unnoticed. An organization that has invested in rigorous quality frameworks encounters the inverse problem: when an upstream source stops delivering data, the quality layer has nothing to evaluate, and the absence propagates silently until a stakeholder report surfaces it.
Neither team made a careless decision. Each approach was deliberate. The problem is architectural – both programs were built to operate independently, and modern data pipelines do not have clean boundaries where one discipline ends and the other begins.
The cost of that architectural separation has compounded. An undetected pipeline failure that once produced a stale dashboard now propagates into AI model inputs, regulatory reporting feeds, and real-time decisioning systems. Gartner estimates poor data quality costs companies an average of $12.9 million per year, and the figure understates the picture in 2026 because it predates the AI workloads that now sit downstream of every broken pipeline.
The question most data organizations are navigating is no longer whether to invest in both. That case is settled. The question is how to make them function as a single operating system rather than two parallel programs that share infrastructure but not context.
What Data Quality Actually Means
Data quality is the measure of whether data is fit for the purpose it serves. It is a judgment about the data itself, not about the pipeline that carries it – a standard the business has agreed on for whether data is accurate, complete, timely, consistent, valid, and unique enough to support the decisions, models, and products that depend on it.
Six foundational dimensions form the operational baseline of any quality program:
- Accuracy– Does the data correctly represent the real-world entity or event it describes?
- Completeness– Are all the required fields populated?
- Consistency– Does the same fact mean the same thing across systems?
- Validity– Does the data conform to defined formats and business rules?
- Timeliness– Is the data current enough to be useful for the decision it informs?
- Uniqueness– Are records free from unintended duplication?
Programs that scale beyond technical compliance extend these dimensions into business accountability. KPIs are calculated on trusted data. Quality gaps are quantified in business cost terms. Data used in financial, operational, and regulatory decisions meets standards that can be audited and defended in front of a regulator or a board.
The line that separates durable quality programs from fragile ones is whether quality is treated as infrastructure or as an activity. A program that defines standards, enforces them continuously, measures the cost when they are breached, and rebuilds trust when they fail is infrastructure – built to scale with the data estate. An activity-based program degrades as the environment evolves, because every new source, schema change, or downstream consumer requires another round of manual review.
The business consequence of poor quality does not care how the program was architected. It cares whether the data was right. Fit-for-purpose is the standard that matters most: not whether data is technically complete, but whether it is usable for the business purpose it was built to serve.
What data observability actually means
Where quality defines the standard, observability is the operational practice of continuously monitoring data as it moves through ingestion, transformation, loading, and consumption – detecting problems before they reach business decisions or AI systems.
The signal types are specific and operationally grounded. Five canonical pillars cover the surface area most teams need:
- Freshness– Has the expected data arrived on time, or has a reporting table gone stale without anyone noticing?
- Volume– Did the pipeline deliver the expected record count, or is a significant drop going undetected?
- Schema– Have structural changes occurred upstream that will silently break downstream consumers?
- Distribution– Are statistical properties of data columns shifting in ways that would degrade a model or skew a report?
- Lineage– What upstream sources feed a given asset, and what downstream systems depend on it?
Some industry definitions add Quality as a sixth pillar – the point at which observability and data quality begin to overlap as disciplines. The overlap is genuine: an observability platform watching for distribution shifts and a quality platform watching for accuracy violations are looking at related symptoms of the same underlying problem. The overlap is also why the two are so often confused. The difference is that observability detects when something has changed; quality judges whether what changed still meets the standard.
Observability extends beyond individual tables. It spans multi-cloud and hybrid environments – Snowflake, Databricks, and cloud storage layers monitored in the same view – and covers full dependency chains, so teams can trace not just what broke but everything affected downstream.
The clean way to draw the line: observability does not judge whether data meets a standard. It detects when something has changed or failed and answers the operational question – what happened and where – so the quality standard can be applied, enforced, and restored.
Why they are not the same – and why that matters
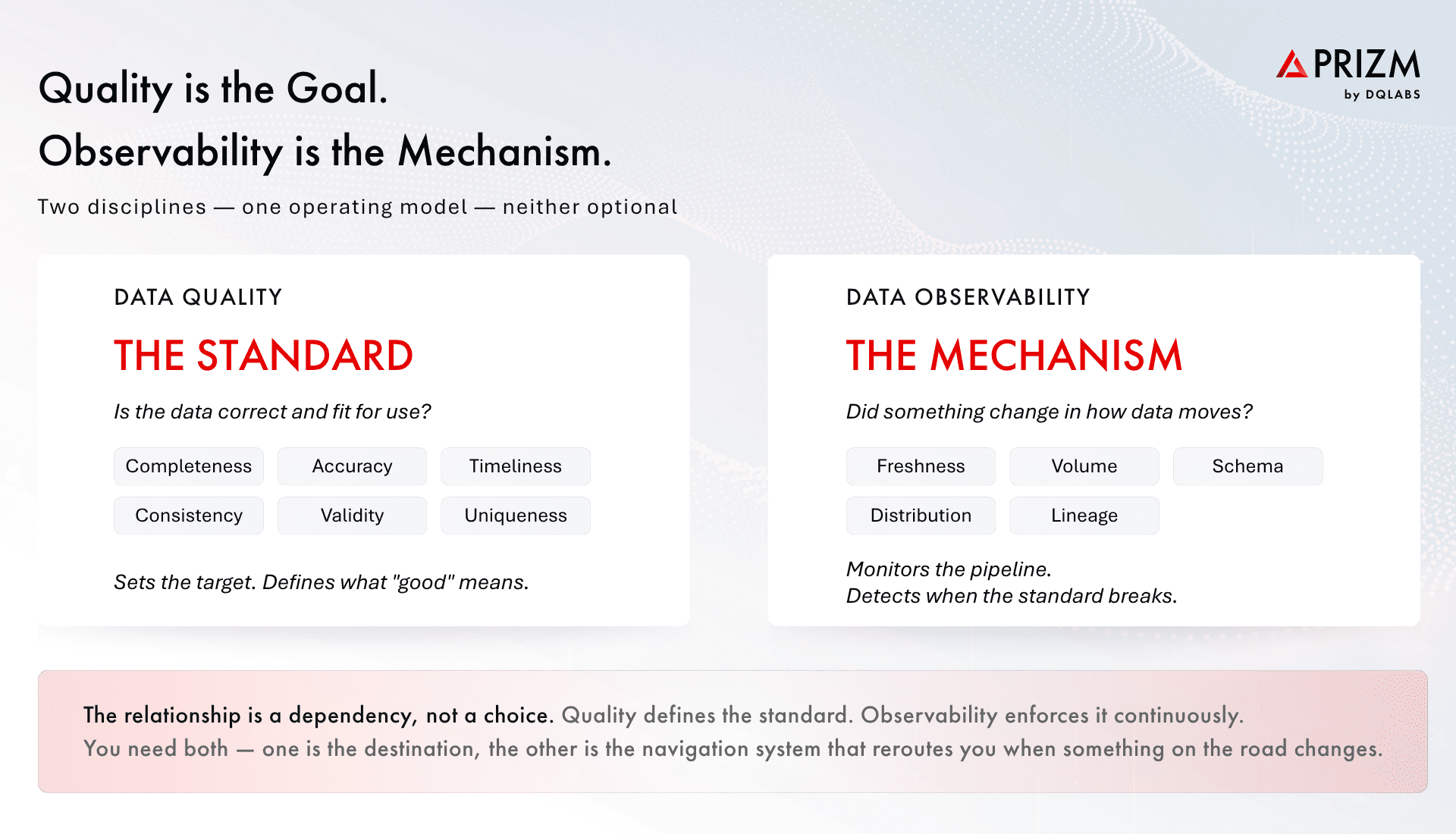
Quality defines what good looks like. Observability provides the operational infrastructure to detect when good has slipped and trace the slip to its source. The relationship is dependency, not competition.
Quality is the goal. Observability is the mechanism.
One is the destination. The other is the navigation system that reroutes you when something on the road has changed. You do not pick between the destination and the way you get there.
Observability generates alerts – raw signals that something has changed or breached a threshold on a specific asset. A mature platform turns those alerts into issues: clustered, context-enriched events that group related signals, identify root cause, assess downstream impact, and prioritize by business criticality. Quality standards determine which issues matter most. The two disciplines operate as a system, not as substitutes.
Which means: if quality is the goal and observability is the mechanism, running them in separate platforms means the goal and the mechanism live in different systems. That separation is the architectural condition behind both failure patterns we see most often.
The two patterns where the gap costs the most
The first pattern shows up in organizations that have invested heavily in quality frameworks but rely on reactive or ad hoc methods for pipeline visibility. Sometimes pipeline monitoring was deprioritized in favor of rule coverage. Sometimes the two concerns were owned by separate teams with limited coordination. When a source system stops delivering data cleanly, there is nothing for the quality layer to evaluate. The absence goes undetected. The issue surfaces through a downstream stakeholder rather than through the platform – at which point the damage has already accumulated across multiple systems and reports.
The second pattern shows up in organizations where observability coverage is broad but the quality framework was not designed with a coherent prioritization model. Often this is the result of programs built incrementally – a new data source added, a new alert configured – rather than designed holistically. Alert volume grows with coverage. Without a clear signal of which assets are business-critical and which anomalies require immediate action, engineering teams operate under sustained triage pressure. The observability investment becomes noise management rather than trust infrastructure.
The architectural fix in both cases is the same: move from alert-centric to issue-centric operations. That shift requires the quality layer to supply the prioritization context that makes issue ranking possible – which means the quality layer and the observability layer have to share the same context graph, in real time, on the same platform.

What the best teams do differently
The organizations that have closed this gap do not run two programs. They have built one operating model in which quality is the KPI and observability is the enforcement mechanism, layered into a single platform that the whole data org uses.
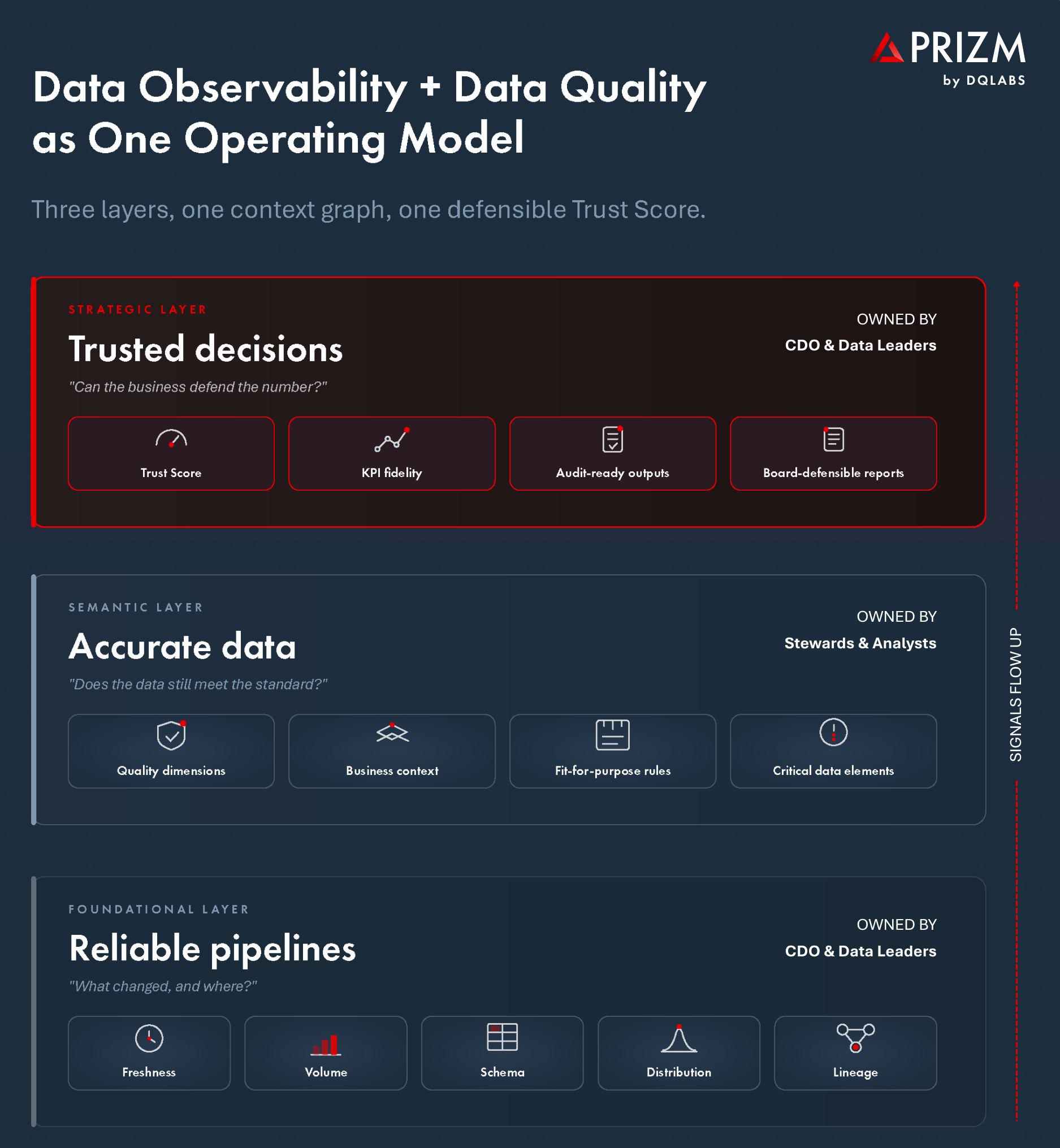
The model has three layers, each with a clear owner and a clear output:
- Foundational layer.Continuous observability across freshness, volume, schema, distribution, and lineage. Owned by data engineers. Output: pipelines that are reliable.
- Semantic layer.Quality standards anchored in business context – what each KPI, attribute, and critical data element is supposed to mean. Owned by stewards and analysts. Output: data that is accurate.
- Strategic layer.Trust scores, KPI fidelity, audit-ready outputs. Owned by the CDO and data leaders. Output: decisions made on data that is trusted.
Signals flow upward through the layers. A foundational anomaly becomes a semantic flag becomes a strategic risk indicator – surfaced on the same platform, on the same context graph, in time to act on. A schema change at the bottom registers as a distribution shift in the middle and lands as a Trust Score dip at the top, all within minutes, because all three layers read from the same continuous monitoring infrastructure.
What changes operationally is the texture of the work. Stakeholders focus on insights and decisions rather than on whether the underlying numbers can be trusted, because trust is maintained continuously rather than verified manually before each meeting. AI systems consume cleaner, timelier data, because pipeline issues are detected and resolved in minutes rather than days. The data platform shifts from generating incident tickets to enabling decisions.
The investment case is direct. Detecting a failure in the pipeline before it propagates is always less expensive than discovering it through a stakeholder complaint.
Why two platforms is the failure mode in 2026
The instinct in most data orgs has been best-of-breed: a tool for observability, another for quality, a catalog for context, a separate alerting layer. The instinct made sense in 2020, when each category was nascent and the integrations between them were workable. It does not survive contact with 2026 architectures.
What the stitched stack actually produces:
- Lineage breaks at vendor boundaries.Observability sees the pipeline. Quality sees the data. Neither sees both. When a downstream report goes wrong, no single tool can trace why.
- Alerts duplicate without correlating.The same upstream failure generates a freshness alert in one tool, a completeness alert in another, a schema warning in a third. Engineers spend the morning reconciling three notifications about one event.
- Semantic context fragments.The business meaning a steward defines in the catalog does not propagate to the rule engine or the anomaly detector. Each tool re-derives context from scratch, badly.
- Ownership splits.When something breaks, the question of which team owns the fix becomes a stand-up agenda item. By the time it is answered, the AI model has already trained on bad inputs.
The unified platform s not a procurement convenience. It is the only architecture in which the operating model from the previous section actually works – because the model requires the foundational, semantic, and strategic layers to share a single context graph, and that graph cannot exist across vendor boundaries.

How DQLabs unifies data observability and data quality
DQLabs built Prizm on the premise that data quality and data observability are not separate problems requiring separate platforms. They are two expressions of the same operational challenge: ensuring data is trustworthy for both human and AI consumers, continuously, at scale.
Prizm is the AI-native, self-driving platform that unifies observability, data quality, and business context into a single control plane. It does not bolt an observability module onto a quality tool. It does not aggregate dashboards from disconnected systems. It treats quality and observability as one operating layer – one platform that monitors pipelines, detects anomalies, enforces quality standards, surfaces the business context needed to act on what it finds, and autonomously resolves the routine issues before they reach a stakeholder.
The output that pulls the operating model together for the CDO is the Data Trust Score – a single, defensible number that rolls observability signals, quality standards, and business context into a measure of how reliable any data asset, KPI, or domain is at any moment. It is the artifact you can show a board, hand to an auditor, or use to greenlight an AI launch.
Frequently Asked Questions
What is the difference between data observability and data quality?
Data quality measures whether data is fit for its intended purpose – accurate, complete, timely, consistent, valid, and unique enough to support the decisions and systems that depend on it. Data observability is the practice of continuously monitoring data through pipelines to detect when and where quality has degraded. Quality defines the standard. Observability enforces it. One is the destination, the other is the navigation system that alerts you when something on the road has changed.
Why do organizations need both – can one replace the other?
Neither discipline substitutes for the other because they answer different questions. Quality asks: is this data correct and fit for use? Observability asks: did something change in how data is moving, and does that change affect quality? An organization with quality frameworks but no pipeline visibility cannot detect when a source stops delivering data – the rules have nothing to evaluate. An organization with observability but no quality model generates alert volume with no benchmark to determine which signals require action. Both are structurally required.
What does it mean to treat data quality as infrastructure?
Treating data quality as infrastructure means embedding continuous, automated quality controls into data pipelines as a permanent operational commitment, not a one-time remediation initiative or a periodic audit. Organizations operating this way define quality SLAs, enforce them with automated checks, monitor for breaches in real time, and measure the business cost when standards slip. Infrastructure-grade quality scales with the data estate. Activity-based quality degrades as the environment evolves, because every new source or schema change demands another round of manual review.
What is the business cost of poor data quality in 2026?
Poor data quality carries costs across three dimensions. Operationally, data teams with underdeveloped quality controls spend a disproportionate share of engineering capacity on reactive incident response. Financially, degraded data fed into AI systems produces wrong answers, forces costly retraining, and invites regulatory scrutiny. Reputationally, stakeholders who encounter unreliable numbers stop trusting the data platform, and rebuilding that trust takes significantly longer than the incident that broke it. The Cost of Poor Data Quality (CPOQ) is one of the metrics that separates scaled programs from reactive ones.
How does data observability relate to AI reliability?
AI systems do not error when their inputs degrade. They produce wrong answers, silently. When a source stops delivering clean data or a schema change breaks a feature store, the model continues running on corrupted inputs without surfacing an explicit signal. Data observability catches these failures before they reach the model. As AI workloads multiply, undetected pipeline failures extend beyond stale dashboards into degraded model performance, incorrect AI-driven decisions, and potential regulatory exposure.