

Summarize and analyze this article with
Your Snowflake estate is growing faster than your ability to trust it. Pipelines are multiplying, credit spend is climbing, and every broken dashboard starts the same forensic scavenger hunt through query history, dbt logs, and lineage graphs. Before you add another monitoring tool to the stack, there are a few things you need to know — because observability built for generic databases will not survive contact with a real Snowflake workload.
1. Why This Platform Changes the Observability Conversation
Why Snowflake Changes the Observability Conversation
Snowflake is not a database in the traditional sense. It is a cloud data platform with a decoupled compute-and-storage architecture, elastic virtual warehouses, a credit-based pricing model, micro-partitioned storage, time travel, dynamic tables, Snowpipe streaming, native apps, Iceberg integration, and an expanding ecosystem of dbt, Coalesce, Streamlit, and BI tools layered on top. Every one of those capabilities is a source of signal — and a potential source of silent failure.
Teams that treat Snowflake observability like relational database monitoring miss the point. A freshness check on a single table tells you almost nothing if the upstream Snowpipe has been silently dropping rows for three days, or if a dbt model deep in the dependency graph is writing to the wrong schema after a recent refactor. Snowflake’s strength — its elasticity, modularity, and speed — is also what makes issues harder to catch. Problems propagate through warehouses, tasks, streams, views, materialized views, and dashboards in minutes. By the time someone notices a number looks wrong on a revenue dashboard, the broken pipeline has already run twice more.
This is why choosing a data observability tool for Snowflake is not a commodity decision. It is a strategic one. The tool you pick will either give your team the leverage to scale data trust across hundreds of pipelines — or it will become another alert fire hose your engineers learn to ignore.
2. What Observability Actually Has to Cover What Snowflake Observability Actually Has to Cover
A common mistake in tool evaluations is narrowing the scope too early. Buyers ask, “Does it detect freshness anomalies on my tables?” and treat that as the core requirement. It is table stakes. The real question is whether the tool can see every layer of the Snowflake stack that can break your data.
At a minimum, modern Snowflake observability needs visibility across seven layers: ingestion, compute, storage, transformation, semantics, consumption, and governance. Each one produces its own signals, its own failure modes, and its own operational cost. A tool that only monitors storage-layer tables will miss pipeline failures that originate in Snowpipe, runaway queries on a multi-cluster warehouse, dbt model test failures, and downstream dashboards that have silently stopped refreshing.
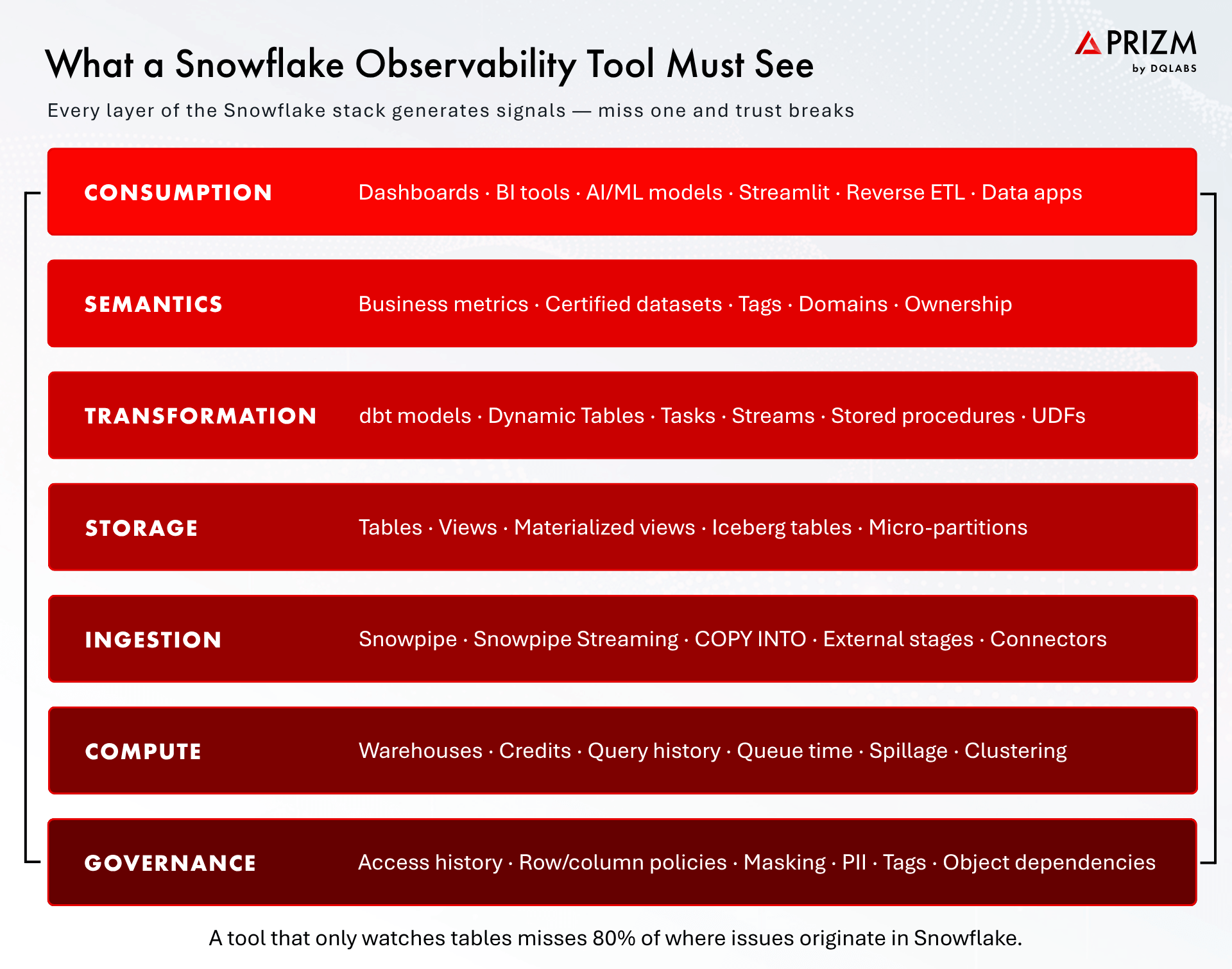
2.1 Ingestion
Snowpipe, Snowpipe Streaming, COPY INTO jobs, external stages, and third-party connectors are the front door of every pipeline. Silent load failures, partial files, malformed JSON, stuck queues, and connector timeouts are all ingestion-layer issues. If your observability tool cannot read pipe status, load history, and stage metadata, it cannot tell you why last night’s tables are short a million rows.
2.2 Compute
Warehouse behavior is the least monitored and most expensive blind spot in most Snowflake deployments. Credits are spent here. Queue time, spillage to local or remote storage, warehouse suspension patterns, multi-cluster scaling thresholds, and runaway queries all live in compute-layer metadata. A Snowflake observability tool that ignores warehouse telemetry is monitoring half the platform.
2.3 Storage
Tables, views, materialized views, and Iceberg tables are where freshness, volume, schema, and distribution checks happen. This is the layer most tools focus on — but even here, quality varies. Micro-partition-level statistics, clustering depth, and table-level DDL history matter for accurate anomaly detection, and not every tool reads them.
2.4 Transformation
dbt models, Dynamic Tables, Tasks, Streams, stored procedures, and UDFs are the connective tissue. A single silent failure in a dbt run or a Task with a bad dependency can cascade into dozens of downstream tables. Observability at this layer means test-level visibility, run metadata, dependency awareness, and — critically — the ability to tie transformation failures back to the tables and dashboards they feed.
2.5 Semantics
Business metrics, certified datasets, ownership, domain tags, and glossary terms are the context layer that separates “alert” from “incident.” A null rate spike on a column is a warning; a null rate spike on the column that feeds the CFO’s revenue dashboard is an emergency. Without a semantic layer, your tool has no way to tell the difference.
2.6 Consumption
Dashboards in Tableau, Power BI, Looker, and Streamlit apps; ML models reading feature tables; reverse ETL pipelines syncing back to operational systems — these are what the business actually uses. A data problem that nobody notices until a stakeholder pings Slack is an observability failure. Tools that trace lineage all the way to consumption catch issues before they reach the user.
2.7 Governance
Access History, row and column policies, masking policies, object tags, and dependencies are how Snowflake enforces trust and compliance. Observability that does not respect these guardrails — or worse, exposes sensitive values in sample data previews and alerts — creates new risk while trying to reduce it.
If a tool you are evaluating only talks about tables, ask what it does about warehouses, pipes, dbt runs, dashboards, and masking policies. The answer tells you whether you are buying observability or just monitoring with a better UI.
3. The Hidden Cost Problem Credit-Aware Observability
Here is a scenario most Snowflake customers have lived through. A new observability tool is rolled out. It starts profiling every table it can find. Deep statistical checks — distribution, uniqueness, correlation, pattern analysis — run on thousands of assets on a nightly schedule. Dashboards light up with metrics. Six weeks later, the FinOps team circulates a concerned email: Snowflake compute spend is up thirty percent, and nobody can explain why.
The answer, in almost every case, is the observability tool. Generic monitoring platforms run the same checks on every asset because they have no way to tell which ones matter. A 50GB dimension table that feeds the executive revenue dashboard gets the same profiling treatment as a long-forgotten staging table from a 2019 migration that nobody has queried in nine months. Both pay the same credit tax. And the long tail of low-value assets — often 60 to 80 percent of the catalog — quietly consumes the majority of your observability budget.
This is why criticality-aware profiling is not a nice-to-have. It is the difference between observability that scales and observability that bleeds credits. A modern Snowflake observability tool should calculate a criticality score for every asset based on usage patterns, upstream and downstream lineage depth, freshness expectations, downstream consumer count, and governance tags like PII or domain ownership. That score then drives the depth of profiling. Critical assets get deep statistical checks, distribution drift detection, and tight SLAs. Low-criticality assets get lightweight polling — or no automated profiling at all.

The impact is dramatic. Criticality-aware approaches typically reduce observability-driven compute spend by 40 to 70 percent while simultaneously improving signal quality, because the alerts that do fire are concentrated on assets that actually matter to the business. If the tool you are evaluating cannot explain how it prioritizes what to profile and at what depth, assume your Snowflake bill is about to grow.
4. Where Silent Failures Actually Live
4.1 Schema Drift Is Where Silent Failures Live
Schema drift is the single most expensive class of data incident in Snowflake environments, and also the most underserved by traditional monitoring. A column gets renamed upstream. A type changes from INTEGER to STRING. A new column is added in the middle of a table. None of these will fail a naive freshness or volume check — but every one of them will quietly break downstream dbt models, dashboards, feature tables, and machine learning pipelines.
The problem is compounded by how Snowflake is used. Engineers iterate quickly. A staging environment is promoted to production. A dbt model is refactored. An analyst creates a view on top of a view on top of a fact table. Each change is legitimate in isolation, but when hundreds of people are making hundreds of changes per week, DDL and DML drift becomes impossible to track manually.
A serious Snowflake observability tool should detect schema changes continuously — ideally every few minutes, not on a daily batch. It should capture DDL events (ADD COLUMN, DROP COLUMN, ALTER TYPE, RENAME, DROP TABLE) and meaningful DML-level shifts (value distribution changes, categorical drift, pattern changes). It should link every detected change to the lineage graph so you can see, instantly, which downstream dbt models, views, and dashboards are now at risk. And it should do all of this without requiring your team to predefine every column and rule manually — because a rules-based approach to schema drift simply does not scale past a few hundred assets.
4.2 Column-Level Lineage — Why Table-Level Is Not Enough
Lineage is where observability becomes intelligence. In a Snowflake environment, a single broken source table can cascade into dozens or hundreds of downstream effects: dbt models that fail silently, tests that pass on stale data, views that return partial results, dashboards that display wrong numbers, ML models that retrain on corrupted inputs, and reverse ETL syncs that push bad data into your CRM.
Table-level lineage is the minimum. It tells you which tables depend on which, but it does not tell you which columns are affected when a specific field changes. Column-level lineage is what you actually need in 2026. When NET_REVENUE_USD is renamed to NET_REVENUE, column-level lineage can immediately identify that 14 downstream models, 7 dashboards, and 2 ML features depend on that exact column — and flag all of them as impacted in seconds. Table-level lineage will tell you that 23 objects depend on the source table, leaving your engineer to hunt through each one manually.
Beyond column depth, Snowflake lineage needs to cross tool boundaries. It needs to include Snowpipe loads, dbt model dependencies, Task and Stream relationships, view and materialized view definitions, and the BI tools that consume the final outputs. Anything less gives you half a map and asks you to guess at the other half when something breaks.
5. Detection — AI-Native vs. Static Thresholds
Rule-based monitoring has a place. It is simple, predictable, and good for hard constraints like “this table must have more than zero rows every morning by 8 AM.” But rule-based approaches fail the moment your data has any seasonality, any natural variance, or any evolution in its patterns — which is to say, always.
Seasonality is everywhere. E-commerce volume spikes on Black Friday. Retail freshness slows on Sundays when stores are closed. B2B APIs go quiet on Christmas Day. A static threshold of “alert if volume drops more than 30 percent” will fire a false positive every weekend for a business with weekday-heavy traffic, and silently miss a genuine outage that happens to occur during a peak hour.
AI-native anomaly detection uses time series models that learn the shape of your data. They build seasonal baselines across daily, weekly, monthly, and quarterly cycles. They adapt as your business grows or patterns shift. They account for trend, not just level. And crucially, they are calibrated per asset rather than globally — because a freshness SLA of 5 minutes for a real-time feature store is not the same SLA as a 24-hour batch dimension table.
When evaluating a Snowflake observability tool, ask how it builds baselines, how it handles seasonality, how long it takes to reach high-confidence detection on a new asset, and how the team overrides or tunes models when the data changes structurally. Tools that answer these questions with specifics are doing real ML. Tools that wave vaguely at “AI-powered” are selling branding.
6. Alert Clustering and Root Cause Analysis
Every production Snowflake environment generates more alerts than any human team can process. A single upstream outage — a failed Snowpipe, a dropped column, a delayed source system — can fan out into hundreds of individual alerts across freshness, volume, null rate, and distribution checks, each one landing in a flat list in Slack or email. Engineers end up investigating the same root cause from five different angles before they realize it is all one incident.
Alert clustering is the capability that fixes this. A mature Snowflake observability tool correlates alerts by time window, by lineage proximity, by asset criticality, and by anomaly type. It collapses thousands of raw signals into a handful of actionable clusters — each one labeled with a likely root cause, a blast radius of affected downstream assets, and a recommended investigation path. In practice, well-designed clustering can compress 3,000 raw alerts into fewer than 20 actionable clusters and a handful of true incidents, without losing a single critical issue.
Root cause analysis goes one step further. Instead of showing you the symptoms, automated RCA traces the alert back through the lineage graph to identify the originating asset, the change that triggered the cascade, and the timeline of how the issue propagated. The best tools do this in seconds rather than hours, and they present the result in a narrative that any on-call engineer can act on — not a raw dependency graph that requires an hour of interpretation.
7. Governance and the Trust Boundary
Snowflake has invested heavily in native governance: object tags, row access policies, column masking, classification, access history, and object dependencies. Any observability tool worth considering should respect and extend this model, not bypass it.
The test is simple. When the tool samples data for profiling, does it honor masking policies? When it shows alerts or writes documentation, does it expose sensitive values? When it generates AI summaries of a table, can it differentiate between a PII-tagged column and a public one? When an engineer queries an AI assistant inside the platform, are responses filtered by the same role-based access controls as the underlying data?
Tools that ignore Snowflake’s native governance create a new surface area of risk. Tools that integrate with it turn observability into a governance accelerator — one that continuously audits lineage, surfaces orphaned tags, flags sensitive data in unexpected places, and reinforces the policies your CISO has already approved.
8. The Autonomous Question Where the Market Is Heading
Every serious Snowflake observability tool in 2026 now talks about automation. The meaningful differentiator is not whether automation exists, but what it actually does and how much control you keep.
At one end, there is passive automation: the tool detects an anomaly and opens a ticket. At the other end is active automation: a multi-agent system that perceives an issue, reasons about its root cause, decides on the appropriate action, and either executes a fix or presents a fully drafted recommendation to a human reviewer with one-click approval. The difference between these two modes is the difference between a tool that notifies you of problems and a tool that resolves them.
The architecture matters. Look for agent-based systems that separate perception (detecting that something changed), reasoning (understanding why and what the impact is), decisioning (choosing the right response), and action (executing safely with auditability). Look for human-in-the-loop controls that let your team set the autonomy level per asset class — full auto for low-risk cleanup, recommend-only for production pipelines, review-required for anything touching finance or compliance. And look for full traceability: every autonomous action should leave an auditable trail that your governance team can review at any time.
9. The Buyer’s Checklist — 10 Capabilities
The Snowflake Observability Buyer’s Checklist
If you are evaluating tools, the list below is the one to bring to every vendor conversation. Score each shortlisted platform against all ten capabilities before you sign anything. The gap between a tool that meets the first four and a tool that meets all ten is the gap between buying another alert source and buying true operational leverage.
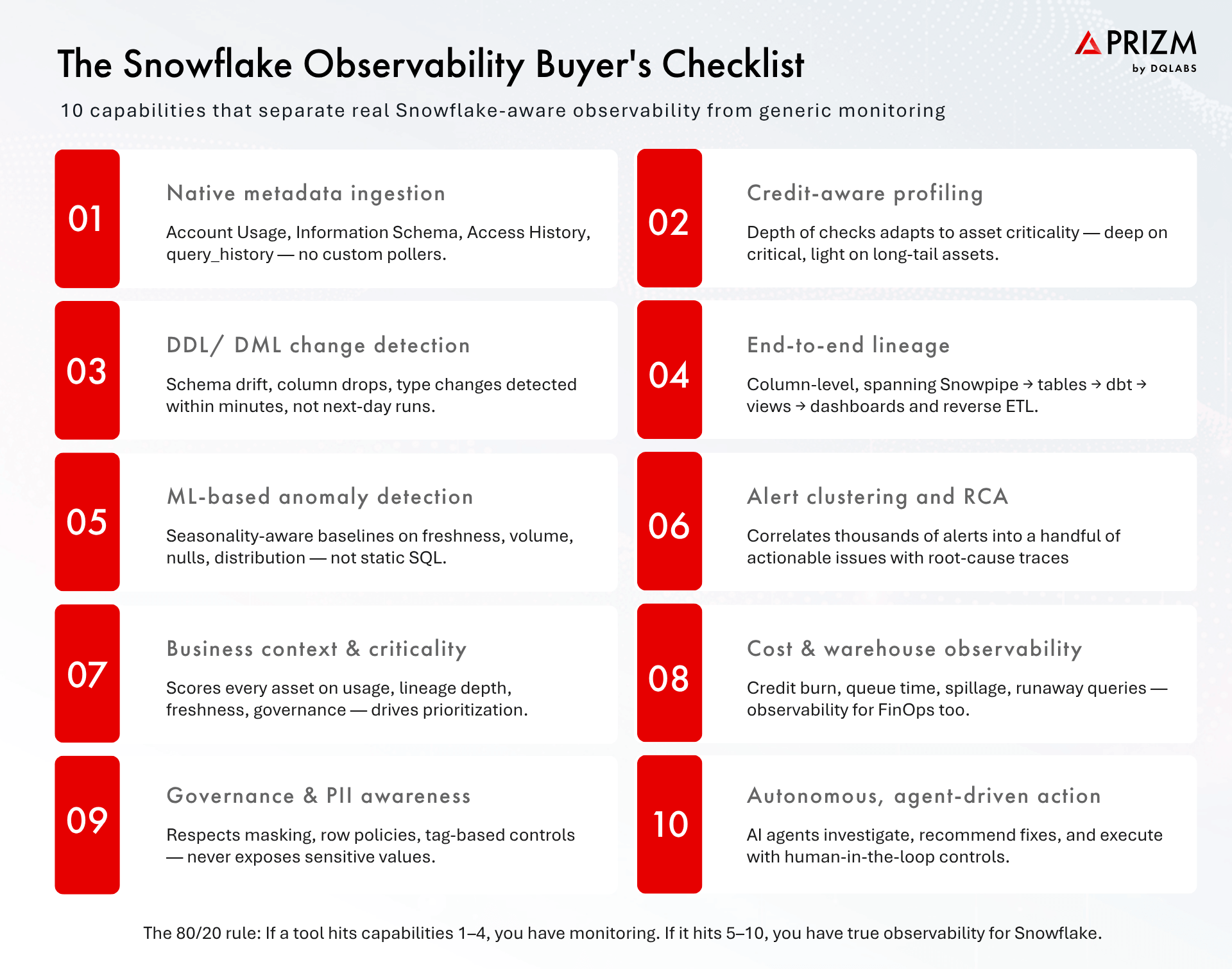
Native metadata ingestion. Direct integration with Snowflake Account Usage, Information Schema, Access History, and query history — no brittle custom pollers.
Credit-aware, criticality-driven profiling. Depth of checks scales with business importance of each asset, not a flat global policy.
Continuous DDL and DML change detection. Schema drift, column changes, and distribution shifts detected in minutes, linked to downstream lineage impact.
End-to-end column-level lineage. Traces data flow from Snowpipe through dbt, views, and Tasks all the way to dashboards, ML features, and reverse ETL destinations.
AI-native anomaly detection. Seasonality-aware, per-asset baselines on freshness, volume, null rate, distribution, and pattern — not static thresholds.
Alert clustering and automated root cause analysis. Thousands of raw alerts collapsed into a handful of actionable clusters with root-cause narratives.
Business context and criticality scoring. Every asset automatically scored on usage, lineage depth, freshness expectations, and governance tags.
Cost and warehouse observability. Credit burn, queue time, spillage, and runaway queries observed alongside data quality — one pane of glass for data and FinOps.
Native governance and PII awareness. Honors masking policies, row access policies, and tag-based controls; never exposes sensitive data in alerts or samples.
Autonomous, agent-driven action. Multi-agent architecture for perception, reasoning, decisioning, and action with per-asset autonomy controls and full audit trails.
10. Red Flags in Snowflake Observability Evaluations
Some things you will hear in vendor demos are worth treating as warning signs. Here are the ones that most often precede a failed rollout.
10.1 “Just write a SQL test and we’ll run it”
If the tool’s core value proposition is that you can define your own rules in SQL or YAML, you are buying a rule engine, not observability. Rules break at scale. The point of modern observability is that the tool figures out the baselines for you on thousands of assets you will never hand-write rules for.
10.2 “We integrate with Snowflake via JDBC”
Generic JDBC access means the tool is treating Snowflake as a commodity relational database. It will not read Account Usage, it will not respect native governance, it will not understand warehouses or credits, and it will not see Snowflake-specific features like Tasks, Streams, or Dynamic Tables. Look for native metadata integration, not generic connectors.
10.3 “Our ML models work out of the box on day one”
Real anomaly detection needs history. A tool that claims perfect detection on day one is either running static thresholds labeled as AI, or it is setting you up for false positives at scale. Ask specifically how long the baseline period is, how the model handles new assets, and how it behaves during known seasonal events.
10.4 “You can always just write a custom Python connector”
Integration gaps are where observability projects go to die. Every connector you have to build yourself is one more piece of undocumented glue code your platform team will own forever. Good tools integrate natively with Snowflake, dbt, major BI platforms, orchestrators, and your catalog — out of the box, with documentation, and maintained by the vendor.
10.5 “We do not interfere with your cost — we only read metadata”
This is sometimes true and sometimes a dodge. Read-only metadata access is lightweight, but any meaningful profiling — distribution, statistics, uniqueness, pattern — runs queries against your warehouses. Ask what queries run, how often, against which warehouses, and what the expected credit impact is for a catalog of your size. A tool that cannot answer precisely is a tool that has not thought carefully about cost.
11. How Prizm Approaches Data Observability for Snowflake
Prizm by DQLabs is built as an AI-native, self-driving platform for data observability, quality, and context — and Snowflake is a first-class environment for every capability the platform delivers. Rather than retrofitting a generic database monitoring model onto Snowflake, Prizm was designed from the metadata up to understand how Snowflake actually works.
Prizm ingests directly from Snowflake’s native metadata surfaces — Account Usage, Information Schema, Access History, query history, and object dependencies — and combines that with metadata from dbt, Tableau, and the rest of the surrounding stack. Every asset is automatically scored for criticality based on usage patterns, upstream and downstream lineage depth, freshness, and governance tags, and that score drives the depth of profiling applied to each one. Critical assets get deep statistical checks; long-tail assets get lightweight polling or none at all. This is how Prizm customers typically see their Snowflake observability spend stay predictable even as their catalog grows into the tens of thousands of assets.
On top of the metadata foundation, a multi-agent architecture — Perception, Reasoning, Decisioning, and Action agents — continuously detects issues across freshness, volume, schema, completeness, distribution, and latency; correlates thousands of raw signals into a small number of actionable clusters; traces each cluster back to a root cause with full column-level lineage; and either executes a remediation or presents a one-click-approve recommendation, governed by per-asset autonomy settings. Every action is audited, every decision is explainable, and every signal is tied back to business context — so the CFO’s revenue dashboard and the stale 2019 staging table are never treated as equally urgent.
The result, in production, is the combination most Snowflake teams are looking for: 99.8 percent alert noise reduction, 60 percent faster mean time to resolution, and zero critical issues missed — without the credit burn that comes from running everything on everything.
12. A Final Decision Framework
If you take one thing away from this guide, let it be this: Snowflake observability is an operating system decision, not a dashboard decision. You are not buying a product that will sit alongside your data platform. You are buying a product that will sit inside it, read its most sensitive metadata, consume its compute, touch its governance controls, and shape how your team spends every hour.
Before you commit, run the shortlist through three questions. First, does the tool understand Snowflake specifically — warehouses, credits, Snowpipe, Tasks, Streams, dbt, native governance — or does it treat Snowflake as a generic database? Second, does the tool scale its effort (and its cost) to the business value of each asset, or does it run the same expensive checks on everything? Third, when something breaks at 2 AM, does the tool tell you what broke and why in under a minute — or does it hand your engineer a list of 400 individual alerts and say good luck?
The tools that answer those three questions well are the ones that turn observability from an operational tax into a strategic accelerator. They are the ones that let your team trust 60, 70, and eventually 80 percent of the data in Snowflake — not just the hand-curated 20 percent. And they are the ones that will still be delivering value when your Snowflake estate is ten times the size it is today.
13. Frequently Asked Questions
What is data observability for Snowflake?
Data observability for Snowflake is the continuous monitoring and analysis of metadata, data quality, and pipeline health across every layer of the Snowflake stack — ingestion (Snowpipe, COPY INTO), compute (warehouses, credits, queue time), storage (tables, views, Iceberg), transformation (dbt, Tasks, Streams, Dynamic Tables), semantics (business context, ownership), consumption (dashboards, ML models), and governance (masking, policies, tags). It goes beyond traditional database monitoring by using AI and lineage-aware intelligence to detect, diagnose, and resolve issues before they reach business users.
How is Snowflake observability different from general data observability?
Snowflake has unique architectural features — elastic virtual warehouses, credit-based compute pricing, micro-partitioned storage, Snowpipe, Tasks, Streams, Dynamic Tables, native governance, and an expanding tool ecosystem — that require observability designed specifically for the platform. Generic data observability tools often treat Snowflake as a commodity relational database and miss warehouse-level telemetry, credit burn, Snowpipe failures, Task dependencies, and native governance policies. True Snowflake observability natively ingests Snowflake metadata and understands platform-specific failure modes.
Why does criticality-aware profiling matter for Snowflake?
Because profiling consumes Snowflake credits. A tool that runs deep statistical checks on every asset in your catalog — including thousands of low-value staging tables, analyst sandboxes, and archived data — can increase Snowflake compute spend by 30 percent or more without adding proportional signal. Criticality-aware profiling scales check depth to each asset’s business importance, typically reducing observability-driven compute spend by 40 to 70 percent while concentrating signal on the assets that actually matter.
What is the difference between table-level and column-level lineage in Snowflake?
Table-level lineage tells you which tables depend on which. Column-level lineage tells you exactly which columns in which downstream objects — dbt models, views, materialized views, dashboards, ML features — depend on a specific source column. When a single column is renamed or dropped, column-level lineage can pinpoint the exact downstream assets affected in seconds. Table-level lineage leaves your engineer manually hunting through every dependent object. In 2026, column-level lineage is the minimum standard for Snowflake observability.
How does alert clustering work in Snowflake observability?
Alert clustering uses AI to correlate thousands of individual alerts — grouped by time window, lineage proximity, asset criticality, and anomaly type — into a small number of actionable clusters, each tied to a likely root cause. A single upstream Snowpipe failure or dbt model break can trigger hundreds of downstream alerts; clustering collapses them into one incident with a clear blast radius. Well-implemented clustering typically compresses several thousand raw alerts into fewer than 20 actionable clusters and a handful of true incidents.
What should I look for in a Snowflake observability tool in 2026?
Ten core capabilities: native Snowflake metadata ingestion, credit-aware and criticality-driven profiling, continuous DDL and DML change detection, end-to-end column-level lineage, AI-native anomaly detection with seasonality awareness, alert clustering and automated root cause analysis, business context and criticality scoring, warehouse and credit observability, native governance and PII awareness, and autonomous agent-driven action with human-in-the-loop controls. A tool that meets the first four is monitoring; a tool that meets all ten is true observability.
Does observability itself consume Snowflake credits?
Yes. Any observability tool that profiles your data — running distribution, uniqueness, correlation, or statistical checks — runs queries against your Snowflake warehouses and consumes credits. The question is not whether it consumes credits, but how much and how intelligently. Tools without criticality-aware profiling apply the same check depth to every asset, driving unnecessary compute spend. Tools with criticality-aware profiling focus compute on high-value assets and can reduce observability-driven credit burn by 40 to 70 percent.
How does AI-native anomaly detection compare to SQL-based data tests?
SQL-based data tests (assertions like “row count greater than zero” or “no nulls in this column”) are useful for hard constraints but cannot handle the seasonality, natural variance, and evolution present in real business data. AI-native anomaly detection uses time-series models that learn each asset’s daily, weekly, monthly, and quarterly patterns, adapts baselines as data evolves, and calibrates per asset. SQL tests have a place; they should complement, not replace, AI-native detection in a modern Snowflake observability program.
Can data observability tools respect Snowflake governance and PII controls?
The best ones do — by honoring masking policies, row access policies, and column tags when sampling data, generating documentation, or surfacing alerts. They should never expose sensitive values outside the same role-based access controls Snowflake enforces on the underlying data. Tools that bypass governance create new risk surfaces; tools that integrate natively with Snowflake’s governance model turn observability into a governance accelerator.
What is autonomous data observability for Snowflake?
Autonomous data observability uses a multi-agent architecture — perception, reasoning, decisioning, and action agents — to continuously detect issues, correlate them into root-cause clusters, and either execute remediation automatically or present one-click-approve recommendations to a human reviewer. The most mature platforms allow per-asset autonomy controls: full automation for low-risk cleanup tasks, recommend-only for production pipelines, and review-required for any asset touching finance, compliance, or regulated data. Every autonomous action is logged for full auditability.
14. Bringing It Together
Snowflake has quietly become the backbone of most modern data organizations — and with that status comes responsibility. Every dashboard the executive team trusts, every model the data science team ships, every customer-facing application that depends on real-time data, all of it now runs on top of Snowflake. Observability is not a checkbox on the data platform roadmap. It is the layer that determines whether the rest of the stack is worth trusting.
The right tool turns that trust into leverage. It gives your engineers back their mornings, your stewards a clear view of what is working, your executives confidence in the numbers they are looking at, and your FinOps team a handle on where compute is going. The wrong tool becomes another alert pipeline nobody reads, another line item on the Snowflake bill, another project that silently gets deprioritized after eighteen months.
Choose with the checklist above. Push every vendor on the red flags. And pick the platform that was built for Snowflake specifically, not the one that claims to work on “any data platform.” The difference shows up on day 30, and it compounds every quarter after that.
Prizm by DQLabs delivers AI-native, self-driving data observability, quality, and context for Snowflake — from native metadata ingestion to autonomous agent-driven resolution, with criticality-aware profiling that keeps credits predictable as your estate grows. Talk to our team to see how Prizm handles a catalog the size of yours.