

Summarize and analyze this article with
What Context Actually Means in Enterprise Data
Context is the most overloaded word in the modern data stack. It appears on every vendor home page, in every analyst deck, and in every architecture diagram, and yet most enterprises cannot describe in operational terms what their context layer actually contains. The result is that context is treated as a synonym for metadata, a synonym for semantic layer, a synonym for catalog, or a synonym for governance, depending on which team is talking. None of those reductions is precise enough to build a serious AI program on.
This article makes context concrete. It defines context as the structured intelligence that surrounds every data asset, breaks it into the seven layers that matter for enterprise operations, and explains what it takes to keep context fresh, trusted, and operationally useful for both human consumers and AI agents.
A Working Definition
Context, in enterprise data, is the answer to a specific question. The question is not “what is this asset” in the technical sense; that is metadata. The question is “what does this asset mean, who relies on it, what state is it in, and is it safe to use right now for the decision I am about to make.” Context is the layer that produces that answer continuously, for every consumer, at every decision point.
A useful test for whether a layer is actually context is whether it can answer three sub-questions simultaneously. Does it tell you what the asset means in business terms? Does it tell you who and what depend on it? And does it tell you what its current trust state is, with the evidence to back the answer? If any of the three is missing, the layer is producing metadata or describing semantics, not delivering operational context.
The Seven Layers of Enterprise Context
Context is not one thing. In a mature enterprise, it is the integration of seven distinct layers, each of which carries different signals and serves different consumers. The layers are interdependent: weakening any one of them weakens the others.
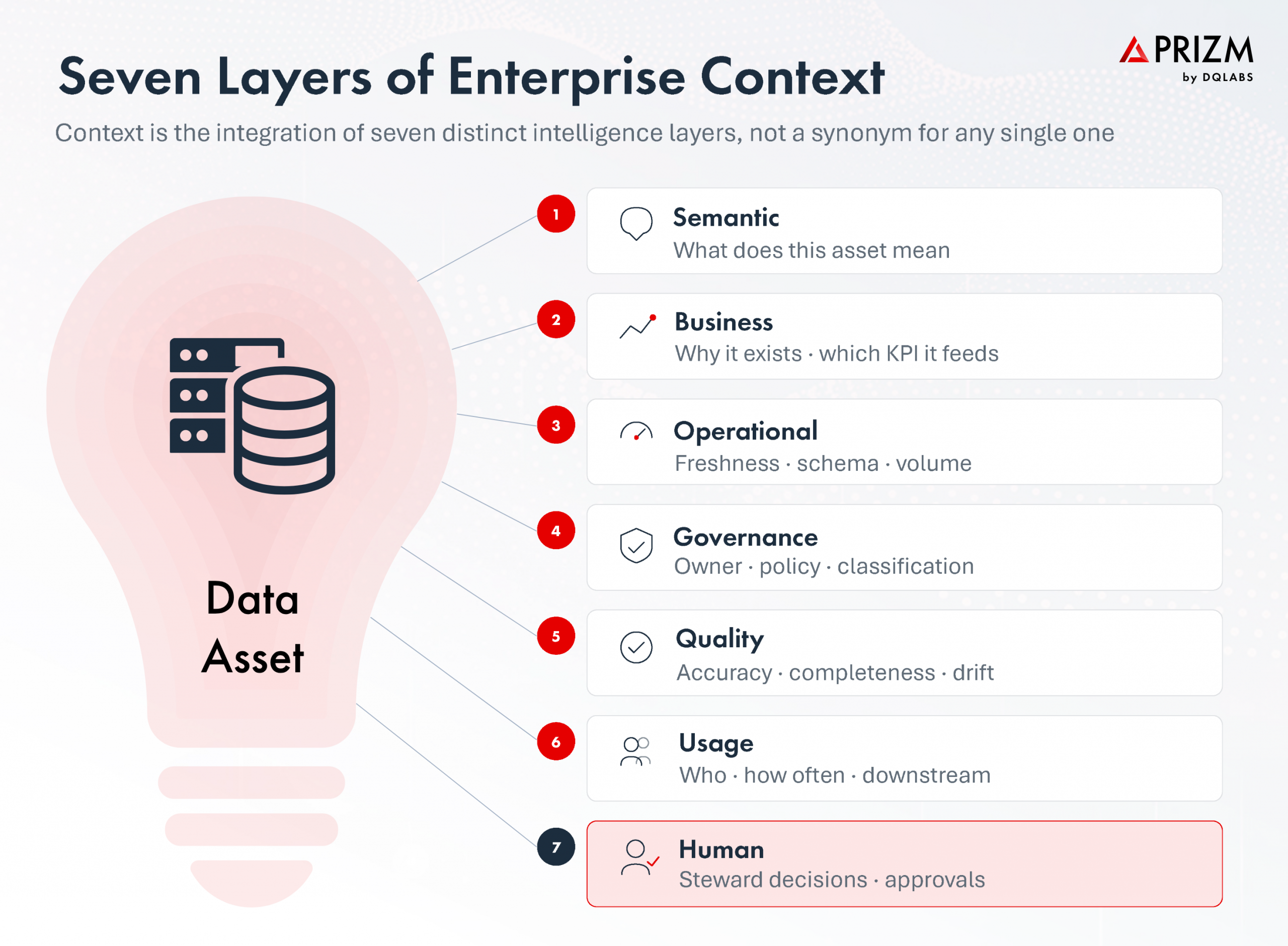
Semantic Context
Semantic context captures the inherent meaning of a data element independent of how it is used. It tells you that a column called cust_id is a Customer Identifier, that it is PII, that it represents the same business entity wherever it appears, and that it carries certain definitional rules. Semantic context is relatively stable, lives in the business glossary and classification layers, and is the foundation other layers build on. Without it, every downstream signal is ambiguous.
Operational Context
Operational context captures how the asset behaves. Freshness, volume, schema cadence, pipeline state, and load history all live here. Operational context is dynamic, refreshed by every pipeline run, and is the layer that observability platforms produce most directly. It tells you whether the asset is doing what it is supposed to be doing, on schedule.
Governance Context
Governance context captures who is accountable and what rules apply. Ownership, classification, policy references, retention rules, compliance posture, and stewardship activity sit here. Governance context is the layer regulators and auditors look at first, and it is the layer that connects technical assets to the human accountability framework around them.
Quality Context
Quality context captures whether the data is correct, complete, valid, and unique, and whether those properties hold across segments rather than only on average. Quality metric results, business quality check outcomes, reconciliation status, reference data lookup performance, and segment-level scores all live here. Quality context is the layer that converts technical correctness into trust signals consumers can act on.
Usage Context
Usage context captures how the asset is actually consumed. Query frequency, distinct user counts, downstream consumption in BI, references from dbt models, citation patterns in reports, and AI agent usage all sit here. Usage context turns asset importance from a static label into a dynamic signal that reflects how the business actually depends on the asset right now.
Human Context
Human context captures what stewards, owners, and domain experts have asserted about the asset. Comments, approvals, exception decisions, ratings, and the stewardship trail are all human context. This is the layer that records what the people who actually understand the data have done with it. It is essential, often undervalued, and frequently lost when programs treat context as a purely automated concern.
Business Context
Business context captures why the asset exists. Which product, service, regulatory submission, or decision relies on it; which KPI it feeds; which workflow it supports; which segment of customers it serves. Business context is the layer that connects the technical estate to the operating model of the enterprise, and it is the layer AI systems most often lack when they fail to produce useful answers.
Why the Layers Have to Operate as One System
The mistake most enterprises make is treating each layer as a separate program. The semantic layer becomes a glossary project. Operational context becomes an observability project. Quality context becomes a data quality program. Governance context becomes a stewardship workstream. Usage context lives in BI analytics. Human context lives in chat threads and tribal knowledge. Business context lives in product owner heads and unstructured documentation.
The result is predictable. Each program produces useful artifacts. None of the artifacts speak the same language. AI agents pulled in to consume the result fail, not because any single layer is wrong, but because they cannot reason across the layers.
Context only delivers operational value when the seven layers are integrated into a single intelligence layer that a human or an AI agent can query through one surface. That is the architectural shift the 2026 catalog category is going through, and that is what platforms positioning themselves around validated context are built to provide.
What Makes Context Trustworthy
A context layer that exists is not the same as a context layer that can be trusted. Three properties separate operationally useful context from context that consumers learn to ignore.
The first is currency. Context that is stale by definition cannot be trusted. A business definition written three years ago, a glossary term updated quarterly, or an ownership record from a long-departed employee are all examples of context that exists but is no longer current. Currency requires continuous evaluation, not periodic curation.
The second is completeness. Partial context invites partial trust. If only a quarter of critical assets have business definitions, only half have known owners, and only a third have quality coverage, consumers default to assuming the layer is unreliable across the board. Completeness has to be measured and surfaced as a coverage signal, not assumed because the platform has good intentions.
The third is reliability. Context has to be defensible under scrutiny. Every assertion in the layer, from a business definition to a trust score, should be traceable to its source and to the stewardship decisions that produced it. Without reliability, the layer becomes opinion at scale, which is exactly the trust trap most active metadata catalogs fell into.
Currency, completeness, and reliability together are what allow consumers, including AI agents, to act on context confidently. They are also the properties that data observability and data quality programs were designed to produce. The integration point matters: a context layer paired with observability and quality signals continuously is what produces validated context. A context layer paired with these signals quarterly produces interesting reports.
Where Prizm Operates in This Picture
Prizm by DQLabs is built to operate the context layer as a single, validated system rather than seven separate programs. DQLabs publicly positions Prizm as an AI-native platform where data observability, data quality, and context work together as one system, and the seven-layer model above is essentially the architectural surface that integration covers.
Prizm captures semantic context through the glossary, classification, and AI-extracted business term capabilities. It captures operational context through autonomous metrics for freshness, schema, and volume. It captures governance context through the stewardship panel, the 273-permission control model, and policy alignment. It captures quality context through autonomous metric deployment, AI-assisted business quality checks, segment analysis, reconciliation, and reference data lookups. It captures usage context through query history, downstream BI consumption signals, and AI agent telemetry. It captures human context through stewardship logs, approval workflows, and comment trails. And it captures business context through domain definitions, data product associations, and the organization persona engine that personalizes AI outputs by role and domain.
The integration matters more than any one capability. The context Prizm produces is not seven separate streams that consumers have to reconcile. It is a single, continuously validated layer that answers, for any asset, what it means, who depends on it, and whether it is safe to use right now, with the trust signals and evidence trail to back the answer. That is what context is supposed to be, and that is what platforms built around the seven-layer integration deliver.
What Data Leaders Should Take From This
Three implications follow for data leaders planning the next phase of their programs.
First, audit the seven layers. Most enterprises have invested heavily in two or three of them and underinvested in the rest. The investments that look most expensive are usually not the missing ones; the missing ones are usually human context, usage context, and the integration glue. The audit reveals where the program is fragmented.
Second, treat context as an architectural decision, not a vendor decision. The question is not which catalog or which observability tool to buy. The question is how the seven layers will be integrated into a single intelligence layer, and which platforms genuinely support that integration rather than producing yet another stream to reconcile.
Third, treat validation as part of the definition. A context layer without continuous validation is not a context layer; it is a metadata store. Validation is what separates the platforms that AI programs will actually rely on from the platforms that AI programs will quietly route around.
Frequently Asked Questions
What is context in enterprise data?
Context is the structured intelligence surrounding every data asset that answers what it means in business terms, who depends on it, and whether it is safe to use right now. It is broader than metadata, broader than the semantic layer, and broader than governance, because it integrates all of those plus operational, quality, usage, and human signals.
What are the seven layers of enterprise context?
Semantic context, operational context, governance context, quality context, usage context, human context, and business context. Each captures different signals; together they form the operational context layer that AI agents and humans rely on.
Why does context need to be validated continuously?
Context that is stale or incomplete cannot be trusted. AI agents in particular fail silently when context drifts. Continuous validation, anchored in observability and data quality signals, is what keeps the context layer reliable enough to act on.
How does Prizm by DQLabs handle the seven layers of context?
Prizm integrates the seven layers into a single, continuously validated context layer. DQLabs publicly positions Prizm as an AI-native platform where data observability, data quality, and context work together as one system, with autonomous metrics, alert clustering, stewardship logging, and AI-readable context surfaces fused into the catalog.
Is context the same as the semantic layer?
No. The semantic layer is one of the seven context layers and captures the definitional meaning of data elements. Context is the broader integration of semantic, operational, governance, quality, usage, human, and business signals.
What happens when a data program treats context as seven separate workstreams?
The seven layers produce useful artifacts that do not speak the same language. AI agents pulled in to consume the result fail, not because any single layer is wrong, but because they cannot reason across the layers. Context delivers operational value only when the layers are integrated.
Where should context live architecturally?
In the layer that already aggregates technical, operational, governance, and business metadata, and that is integrated tightly with observability and data quality so the context can be validated continuously. The modern catalog category is moving toward this profile, and platforms like Prizm by DQLabs are built around it directly.