

Summarize and analyze this article with
Snowflake has revolutionized data warehousing with its scalable, secure cloud-based platform for storing and analyzing massive datasets. It’s fast and easy to use – but have you ever considered how the quality of your data could make or break your Snowflake projects? In a Snowflake environment, poor data quality can lead to inaccurate insights, flawed decision-making, and ultimately lost revenue. Ensuring high data quality is not automatic even in a modern warehouse like Snowflake – it requires the right tools and practices.
In this blog, we’ll explore common data quality challenges in Snowflake, best practices to maintain data integrity, and how the DQLabs platform can help you achieve and sustain trusted, high-quality data in Snowflake.
What you will learn
- Snowflake offers native data quality tools (DMFs, profiling) but requires manual setup and has limited real-time monitoring.
- Common challenges include data ingestion errors, schema changes, lack of lineage, and governance gaps.
- Maintaining data quality demands automation, governance, embedding checks in pipelines, and fostering a data quality culture.
- DQLabs enhances Snowflake by providing automated, continuous data profiling, cleansing, and anomaly detection with AI-powered insights.
- DQLabs adds real-time alerts, data lineage tracking, and governance features like access controls and role assignments.
- The integration improves data trustworthiness, reduces errors, automates manual tasks, and accelerates decision-making.
- Together, Snowflake and DQLabs enable scalable, reliable, and compliant data management for better analytics outcomes.
What is Snowflake Data Quality Monitoring?
Snowflake recently introduced a native Data Quality Monitoring feature that enables users to implement automated data quality checks within the Snowflake Data Cloud. At the core of this feature are Data Metric Functions (DMFs)—pre-built and custom SQL-based metrics that track key data health indicators.
Snowflake provides system DMFs to monitor common quality attributes like null values, value ranges, uniqueness, and data freshness. Additionally, users can define custom DMFs to enforce business-specific rules by writing SQL-based functions.
However, it’s important to note that Snowflake’s Data Quality Monitoring is only available in Enterprise Edition and above. While it offers a starting point for ensuring reliable data, it’s not a complete solution. Next, let’s explore the fundamentals of data quality and why maintaining it in Snowflake requires more than just native monitoring.
Understanding Data Quality in Snowflake
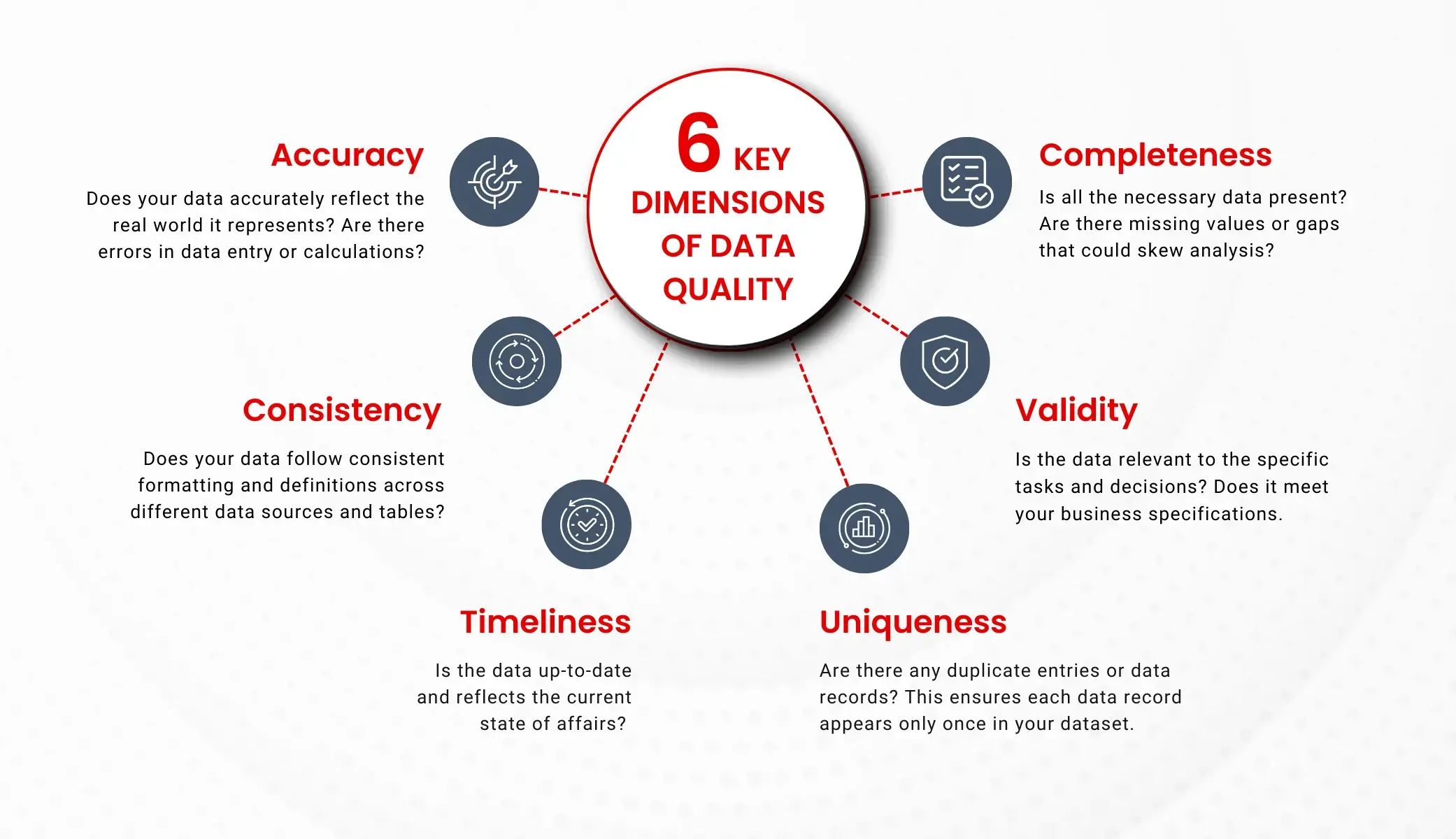
Before diving deeper, let’s define data quality—the overall health and reliability of data for its intended use, typically measured across key dimensions:
- Accuracy: Does the data correctly reflect real-world values?
- Completeness: Are all required records and fields present?
- Consistency: Is the data uniform across tables and sources?
- Validity: Does it adhere to defined formats and rules?
- Uniqueness: Are there duplicate records when there shouldn’t be?
- Timeliness: Is the data fresh and available when needed?
Even with Snowflake’s robust platform, data quality is not inherently guaranteed. Here’s why ensuring it is crucial:
- Insight Accuracy: Snowflake’s speed doesn’t fix bad data—flawed inputs lead to misleading insights, just faster.
- The Domino Effect: A single ingestion error can cascade through reports, causing costly mistakes.
- Governance Gaps: Uncontrolled schema changes, inconsistent data versions, or unauthorized modifications undermine trust and compliance.
Common Data Quality Challenges in Snowflake
Users frequently face issues like:
- Data Ingestion Errors: Duplicates, missing fields, or format inconsistencies from diverse sources.
- Schema Changes: Renaming columns or altering types can break downstream workflows.
- Incomplete Data: Failed processes or partial updates lead to analysis gaps.
- Lack of Data Lineage: Troubleshooting errors is difficult without knowing data origins.
- Poor Governance: Unrestricted access and inconsistent definitions create chaos.
- Storage Bloat: Excessive, unmanaged data increases costs and reduces clarity.
Maintaining high data quality in Snowflake requires proactively addressing these challenges. While Snowflake provides built-in monitoring, understanding its capabilities and limitations is key—let’s explore what it offers and where it falls short.

Snowflake’s Data Quality Monitoring Features
Snowflake provides several built-in capabilities for data quality monitoring, primarily through Data Metric Functions (DMFs) and governance tools:
- System DMFs measure key indicators like null values, freshness, duplicates, and basic data profiles—offering automated insights into data health.
- Custom DMFs allow users to define SQL-based data quality rules for business-specific checks, with results stored for auditing and trend analysis.
- Snowsight Data Profiling provides basic column-level statistics to quickly identify anomalies but lacks continuous monitoring.
- Governance Features like data masking, object tagging, and access history logs enhance data integrity and help detect unauthorized modifications.
While Snowflake offers valuable tools to improve data quality – but using them effectively requires effort, and they might not cover every need. Let’s examine some of the limitations you should be aware of when relying solely on Snowflake for data quality and observability.
Limitations of Snowflake
For Data Quality
Snowflake provides a range of features designed to classify, secure, and validate data (as described above), but these often require significant manual intervention and SQL coding from your data engineering team. Defining data quality rules via DMFs or stored procedures means writing and maintaining a lot of SQL code. Every new dataset or quality requirement might entail developing new queries or functions. This approach can become labor-intensive and hard to scale across an enterprise environment. Collaboration and maintenance suffer when rules are scattered across scripts, and presenting the results in a user-friendly way (for business stakeholders) is not trivial – Snowflake will record the outcomes, but it’s up to you to build dashboards or reports from them.
Another challenge is that Snowflake’s built-in tools focus on data within the warehouse’s structure and known schema. They excel at managing data that conforms to your predefined models, but may not fully address the needs of agile data exploration and rapid prototyping. Often, data science teams or ad-hoc analysts will load new data sets or create temporary tables in Snowflake to explore – these might not have strict quality checks upfront. Mistakes or outliers can slip in during these fast-paced experiments. Snowflake doesn’t automatically catch those, especially if they occur outside of a formal ETL process. In short, unknown or unexpected data changes can evade Snowflake’s manual rule-based checks until a problem becomes obvious in results.
Even the new Data Quality Monitoring feature has constraints. Each table or view can only have one DMF schedule associated with it, which means you must bundle multiple checks together (potentially reducing flexibility for different checks on different timings). Also, running DMFs isn’t free – they consume compute credits when executed. If you set up many data quality monitors, you could incur noticeable Snowflake usage costs purely for quality checks. These factors can limit how extensively an organization chooses to deploy native quality rules across all data assets.
For Data Observability
Ensuring data quality isn’t just about writing checks – it’s also about having visibility into your data pipelines and being alerted to issues in real time. This is an area where Snowflake’s native offerings are currently limited. Snowflake’s primary interface, Snowsight, gives only a basic view of data status and no real real-time alerting. You can see table statistics and some query performance metrics, but you won’t get proactive notifications if data anomalies occur (for example, if yesterday’s load had 20% fewer records than usual, Snowflake itself won’t text or email you about it).
Many Snowflake users resort to external scripts or manual processes for monitoring. They might write custom ETL validations in Python or use SQL queries to check for certain conditions after data loads, then manually review results or send out emails. Others leverage business intelligence tools like Tableau, Looker, or Power BI to do periodic checks (for instance, a dashboard showing row counts by day). However, these approaches are not true observability solutions – they often lack real-time capabilities and require the engineer or analyst to remember to look at them. BI tools are meant for reporting to end-users, not for behind-the-scenes monitoring of data pipeline health, so they lack features like automatic anomaly detection, alert thresholds, and detailed operational metrics.
Snowflake’s automation conveniences (like automatic clustering, partitioning, and scaling) can also inadvertently obscure issues. For example, Snowflake will happily ingest data and adjust performance under the hood, but if a subtle data error occurs – such as a mix-up in date formats or a case sensitivity issue that causes duplicate entries – Snowflake won’t flag it as an error. The pipelines won’t break, but your data quality will suffer silently. Traditional data management or governance tools that just consume Snowflake’s logs might miss these nuances too, because they’re not checking the data content deeply; they’re often just checking that a load job ran or how many rows were loaded, not whether those rows make sense.
Even Snowflake’s own data profiling and monitoring outputs are point-in-time. For instance, the Data Profiler in Snowsight or even a DMF check will tell you the state at the moment it ran. If a data issue arises an hour later, you won’t know until the next scheduled run or the next time someone manually looks. There is a lack of continuous, end-to-end observability where data is validated at every stage and alerts are raised the instant something goes awry. This means data errors that occur between scheduled checks or outside expected scenarios can go unnoticed for too long, undermining trust in your Snowflake data.
In summary, Snowflake’s native capabilities, while improving, do not yet provide comprehensive real-time data quality control and observability. Organizations using Snowflake need to supplement Snowflake’s tools with robust practices or additional platforms to achieve the level of data quality assurance they require.
Best Practices for Ensuring Data Quality in Snowflake
Maintaining high data quality in Snowflake requires leveraging native tools and best practices:
- Leverage Snowflake’s Native Quality Tools: Use Data Quality Monitoring (DMFs) and Snowsight’s profiler for basic checks like null values, freshness, and duplicates. Regularly review and update these rules as data evolves.
- Establish Clear Data Governance: Assign data owners, implement access controls, and enforce naming conventions to prevent inconsistencies and unauthorized changes. Clear governance minimizes chaos and enhances data trust.
- Automate Data Quality Checks and Monitoring: Schedule automated validation queries using Snowflake tasks or third-party tools to detect anomalies and trigger alerts. This ensures timely issue resolution without manual oversight.
- Regularly Profile and Audit Your Data: Conduct routine profiling and audits to catch schema mismatches and unexpected data drifts early. Encourage analysts to validate datasets before use.
- Integrate Quality Checks Into Data Pipelines: Add pre-load, post-load, and transformation checks within ETL/ELT workflows. Embed quality assertions in SQL scripts to prevent bad data from flowing downstream.
- Foster a Data Quality Culture: Educate teams on data quality importance, encourage proactive validation, and establish a feedback loop where downstream users report issues to upstream owners for resolution.
A layered approach combining Snowflake’s tools, governance, automation, and culture significantly reduces data quality risks and ensures reliable insights.
How DQLabs Enables High-Quality Data in Your Snowflake Ecosystem
Implementing best practices for data quality in Snowflake can be complex and time-consuming. DQLabs simplifies this process by providing an automated, end-to-end data quality and observability platform that seamlessly integrates with Snowflake. By leveraging DQLabs, organizations gain real-time insights into data health, automate data quality processes, and ensure their analytics are built on trustworthy information.
DQLabs enhances Snowflake’s capabilities by adding intelligence, automation, and governance to data management. Here’s how DQLabs helps improve data quality and observability in your Snowflake environment:
Key Features of DQLabs for Improved Data Quality & Observability
Data Profiling and Assessment
DQLabs performs deep data profiling across Snowflake assets, automatically scanning structures, capturing metadata, and understanding data relationships. It continuously profiles data, detecting anomalies and inconsistencies.
With over 50 built-in data quality checks, DQLabs evaluates accuracy, completeness, consistency, validity, uniqueness, and timeliness. This ensures immediate issue detection without requiring manual rule configurations.
Data Cleansing & Standardization
Beyond identifying data issues, DQLabs provides robust tools to fix them. It detects typos, duplicates, format inconsistencies, and invalid entries, offering automated remediation and guided workflows.
DQLabs enforces standardization across Snowflake, ensuring uniform naming conventions, formats, and structures. The platform’s semantic layer understands data context, enabling consistency across all datasets.
Discover How DQLabs Can Help You Maximize Your Snowflake Investment
DQLabs goes beyond data quality checks by providing insights into Snowflake usage. It helps optimize costs by identifying redundant data, flagging inefficient processes, and ensuring high-quality data powers analytics.
Data Governance Framework
DQLabs strengthens governance by enabling clear data ownership, access controls, and compliance measures. Features include:
- Assigning data stewards and tracking accountability.
- Implementing role-based access controls and data masking.
- Enforcing business rules and thresholds to maintain data integrity.
DQLabs ensures governance is an active, automated part of Snowflake, keeping data consistent and compliant.
Continuous Data Monitoring
DQLabs offers real-time dashboards that track key data quality metrics, providing a comprehensive health check of Snowflake data. Intelligent alerts notify teams when quality issues arise, integrating with tools like Slack, Microsoft Teams, and email.
AI-powered anomaly detection prioritizes alerts based on severity, reducing noise and preventing alert fatigue. When issues occur, DQLabs provides root-cause insights, allowing teams to resolve problems faster.
Data Lineage Tracking
Understanding data lineage is crucial for diagnosing issues and maintaining trust. DQLabs automatically maps how data flows between sources, Snowflake tables, and downstream BI tools.
- Tracks upstream and downstream impacts of data issues.
- Detects schema changes and data drifts, alerting teams proactively.
- Maintains a version history of schema modifications for compliance and auditing.
By providing a complete view of data movement, DQLabs ensures full transparency and trust in Snowflake data.
Machine Learning-Powered Data Quality
DQLabs leverages machine learning to enhance data quality management. Unlike traditional rule-based checks, ML techniques help detect unexpected anomalies and improve data validation.
- Learns normal data behavior and flags deviations.
- Provides intelligent rule recommendations based on data context.
- Automates rule enforcement, reducing manual effort.
The platform continuously adapts to data changes, ensuring evolving data quality needs are met with minimal manual intervention.
DQLabs and Snowflake Work Better Together
By integrating DQLabs with Snowflake, organizations unlock a powerful combination that enhances data quality, governance, and efficiency:
- Improved Data Quality: Detects and remediates data issues automatically, ensuring Snowflake data remains clean and reliable.
- Reduced Errors and Bias: Proactive monitoring catches errors early, reducing data inconsistencies and biases.
- Enhanced Governance: Enforces data governance policies seamlessly within Snowflake, improving compliance and auditability.
- Increased Operational Efficiency: Automates manual tasks like profiling, cleansing, and alerting, freeing up valuable resources.
- Faster Time-to-Insight: Reliable data eliminates the need for constant validation, accelerating decision-making and analytics.
Snowflake provides a robust cloud data platform, but maintaining high-quality data requires continuous monitoring and refinement. DQLabs automates this cycle, ensuring data remains accurate, complete, and trustworthy.
Schedule a personalized DQLabs demo today and experience augmented data quality and observability in your Snowflake environment.
FAQs
What is Snowflake Data Quality Monitoring?
Snowflake Data Quality Monitoring (available in Enterprise editions) enables automated checks on Snowflake data using Data Metric Functions (DMFs). These metrics track missing values, duplicates, value ranges, and data freshness. You can attach them to tables or views, and Snowflake executes them on a schedule or when data changes, logging results. While it provides basic monitoring, setting up metrics requires SQL, and alerts need external integration.
How can I automate data quality checks in Snowflake?
You can automate checks in Snowflake by:
- Using DMFs to define and schedule quality rules.
- Setting up Snowflake Tasks to run SQL validation queries and log issues.
- Integrating third-party tools like DQLabs, which automate monitoring, provide AI-driven insights, and send real-time alerts (email, Slack, etc.).
Most organizations use a hybrid approach—leveraging Snowflake’s built-in tools for basic checks and external platforms for advanced monitoring and automation. The key is continuous, hands-free monitoring with alerts to catch issues early.
Focusing on these dimensions helps organizations pinpoint where data might be failing. For instance, data could be accurate but not timely, or complete but not consistent across systems. A robust data quality program aims to optimize all of these dimensions for its critical data assets.
What are some best practices for maintaining data quality in Snowflake?
To ensure high data quality in Snowflake:
- Establish data governance – Assign data owners, enforce access controls, and document schemas.
- Use Snowflake’s quality features – Set up DMFs and Snowsight profiling for automated checks.
- Integrate validation in pipelines – Run pre-load/post-load checks and use Great Expectations to test assumptions.
- Monitor continuously – Use scheduled queries or observability tools to track timeliness, completeness, and consistency, with alerts for anomalies.
- Perform regular audits and cleanups – Remove obsolete data, update quality rules, and analyze error logs for recurring issues.
- Leverage automation and tools – Use AI-powered data quality platforms like DQLabs to streamline anomaly detection and rule enforcement.