

Summarize and analyze this article with
Data warehouse architecture is the blueprint for how an organization structures its data storage, integration, and access for analytics. A well-designed architecture turns raw data into a powerful asset, enabling business intelligence (BI) and data-driven decisions.
In this blog, we’ll explore what data warehouse architecture is, why it’s important, its key components and layers, and how modern approaches compare to legacy designs. We’ll also cover best practices, challenges, and real-world examples to help you design an efficient, future-ready data warehouse architecture.
What is Data Warehouse Architecture?
Data warehouse architecture refers to the overall design and organization of a data warehouse system. It defines how data flows from source systems into the warehouse and ultimately to the tools used by end users. It includes all components, processes, and standards that ensure data is collected, transformed, stored, and made consistently accessible for analysis.
It acts as a blueprint that shows how raw data is extracted, cleaned, stored, and delivered to business analysts and other consumers for reporting and insights.
Importance of Data Warehousing in Business Intelligence
A good data warehouse is the backbone of BI. Here’s why:
- Single Source of Truth: It brings all your data into one place. No more siloed systems. Everyone works off the same numbers.
- Historical Analysis: Warehouses store years of data, enabling trend analysis, forecasts, and strategic planning.
- Fast Queries: Designed for analytics, warehouses handle large queries better than operational systems.
- Smarter Decisions: With reliable, consistent data, leaders make informed calls—not gut guesses.
- Advanced Analytics: Modern warehouses support not just BI dashboards but also AI/ML, thanks to clean, structured data.
How Data Warehouses Differ from Databases
It’s common to wonder how a data warehouse is different from a regular database. After all, both store data in tables. The distinction lies in their purpose, design, and usage. Understanding these differences is key when planning your data strategy.
| Aspect | Database (OLTP) | Data Warehouse (OLAP) |
|---|---|---|
| Primary Use | Runs day-to-day business operations (e.g., order processing, inventory updates). | Supports analytics, reporting, and business intelligence with historical data. |
| User Type | Used by business applications and transactional systems. | Used by analysts, BI tools, and data teams. |
| Workload Optimization | Optimized for frequent writes, inserts, and updates. | Optimized for reads, aggregations, and complex queries. |
| Schema Design | Highly normalized (e.g., 3NF) to reduce redundancy and ensure consistency for transactional integrity. | Denormalized (e.g., star or snowflake schema) to enable faster querying and analysis. |
| Data Scope | Focuses on current data and recent transactions; often application-specific. | Contains large volumes of historical data from across the organization. |
| Data Retention | Short-term data; older records are often archived or purged. | Long-term storage; designed to maintain time-variant historical snapshots. |
| Query Performance | Not ideal for analytical queries; complex joins can slow down performance and affect operations. | Built to handle analytical queries efficiently with features like columnar storage and MPP. |
| Architecture Goal | Ensure consistency and speed in transactions. | Enable fast, reliable insights from large, integrated datasets. |
| Data Consistency & Quality | Managed within siloed systems; quality can vary between systems. | Centralizes and cleans data from multiple sources using ETL and business rules for consistent reporting. |
| Observability & Monitoring | Typically limited to application-level monitoring. | Emphasizes data observability – tracking data health and trustworthiness across pipelines. |
| Role in Data Strategy | Powers the systems that run the business. | Powers the analysis that guides strategic decisions. |
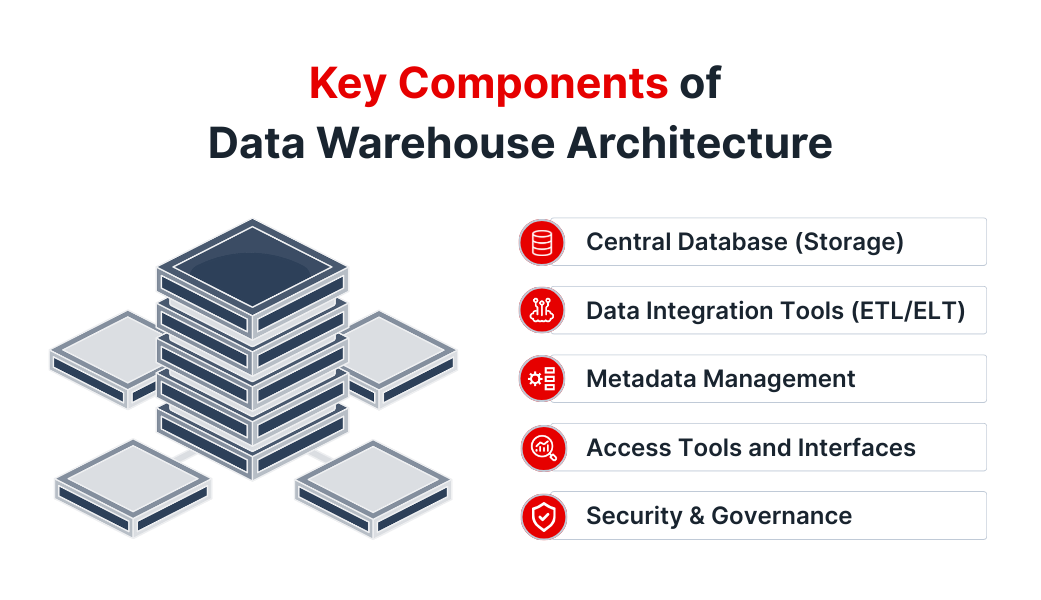
Key Components of Data Warehouse Architecture
1. Central Database (Storage)
The core of the architecture, where integrated data is stored for analysis—commonly built on relational or cloud-native systems like Snowflake or Redshift.
2. Data Integration Tools (ETL/ELT)
Tools that extract data from source systems, transform or load it into the warehouse, and ensure it’s clean, unified, and analysis-ready.
3. Metadata Management
Organizes technical and business metadata to enable data discovery, lineage tracking, and consistent reporting.
4. Access Tools and Interfaces
Includes BI tools, OLAP servers, data science notebooks, and APIs that allow users to query, visualize, and consume data.
5. Security & Governance
Controls access, enforces data policies, and ensures compliance across all components of the architecture.
Types of Data Warehouse Architectures
Data warehouse architectures vary by layers (or “tiers”) and deployment models. Traditionally, they’ve been categorized as single, two, or three-tier designs, with modern approaches evolving to cloud-native and real-time setups.
Single-Tier Architecture
Single-tier architecture aims to minimize redundancy by merging operational and analytical systems into one layer. It uses a single data store for both current and historical data, handling transactions and analytics together.
While simple in theory, it’s rarely used in practice. The lack of separation means analytical queries can slow down operational systems, and data can’t be cleaned or transformed effectively. You might see this model in small setups or in virtualized environments, but most implementations move beyond it quickly due to performance and maintenance limitations.
Two-Tier Architecture
Two-tier architecture introduces a separate data warehouse layer. Data is staged, transformed, and stored in a central repository, which users access directly through BI tools. This structure reduces strain on operational systems and supports better data quality through staging. However, without a middle layer to distribute processing, scalability becomes a challenge as users and queries grow. Many early enterprise warehouses followed this model before evolving to a more scalable three-tier design.
Three-Tier Architecture
The three-tier architecture is the most popular data warehouse model, consisting of three layers:
- Bottom Tier – Data Storage: This is the central repository where transformed, cleansed data is stored (often in a relational DB or specialized warehouse engine).
- Middle Tier – Application/Analytics Layer: Here, an OLAP server or analytics engine processes the data. It structures it into optimized forms like cubes or aggregated views for faster queries, abstracting raw data from users.
- Top Tier – Presentation/Client Layer: This is where users interact with the system via BI tools, dashboards, or custom apps. The middle tier processes requests from users, runs the queries, and returns results for display.
The three-tier setup offers scalability and performance by offloading heavy computations to the middle layer, allowing more users to access data concurrently without taxing the storage layer. It’s commonly used in large-scale data warehouses and continues to be used in modern cloud-based systems as well.
Layers in Data Warehouse Architecture
Data warehouse architecture is typically broken down into these logical layers:
- Data Source Layer: The origin of data, including CRMs, databases, and external sources, from which data is extracted via connectors or APIs.
- Staging Layer: A temporary space where raw data is cleaned and transformed (e.g., removing duplicates, standardizing formats) before entering storage.
- Storage Layer: The core of the warehouse, where transformed data is stored long-term in schemas optimized for analysis and reporting.
- Presentation Layer: The interface for end-users to interact with data, usually through BI tools, dashboards, or data marts, providing simplified views for analysis.
These layers ensure data flows efficiently, from source to presentation, with each layer performing a specific function to optimize the overall process.
Best Practices for Building an Efficient Data Warehouse
Building a data warehouse is complex, but following these best practices can help ensure success:
- Align with Business Goals and Engage Stakeholders Early
Involve key stakeholders from the start to define objectives and metrics. Gather feedback regularly to ensure the warehouse meets business needs. - Choose the Right Architecture and Tools
Select an architecture based on volume, complexity, and security needs. Choose tools that fit your team’s skillset and plan for scalability. - Emphasize Data Quality and Governance
Set validation rules, monitor pipeline health, and maintain a data catalog. Implement data security and privacy policies to ensure trust and compliance. - Design for Scalability and Performance
Plan for future growth by using efficient schema models, optimizing ETL workflows, and implementing summary tables for faster queries. Take advantage of cloud scalability and regularly test performance to identify potential bottlenecks. - Implement Robust Security and Access Control
Use role-based access controls (RBAC), data encryption, and multi-factor authentication (MFA). Ensure compliance with privacy regulations like GDPR. - Plan for Maintenance, Monitoring, and Continuous Improvement
Monitor ETL performance, optimize queries, and review usage patterns. Keep documentation up to date, use agile development, and ensure backup and recovery plans are in place.
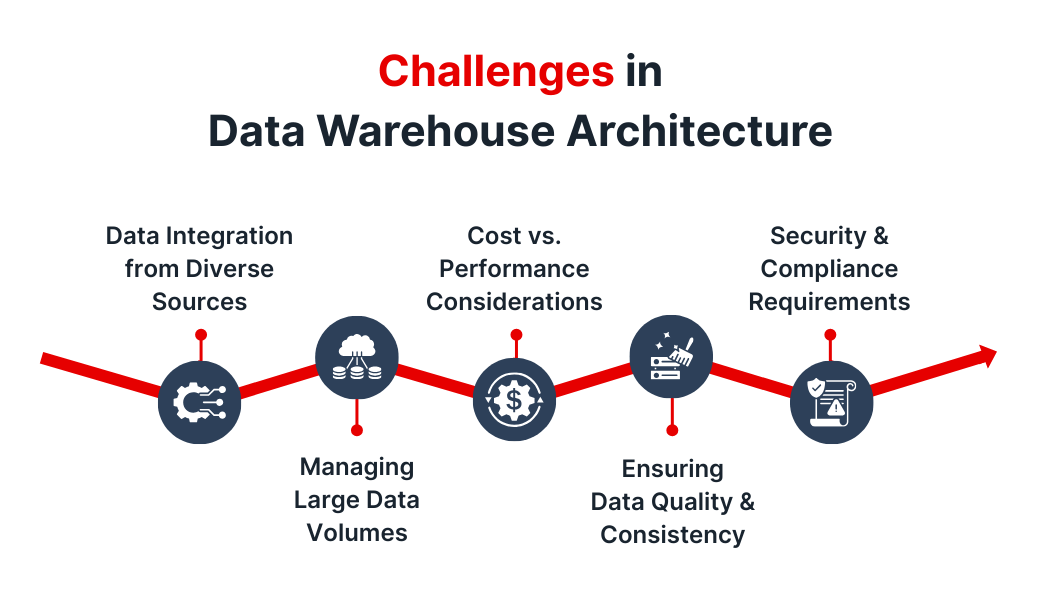
Challenges in Data Warehouse Architecture
Building and maintaining a data warehouse comes with several challenges. Here’s a breakdown of the key pain points:
1. Data Integration from Diverse Sources
- Data Format Mismatch: Different systems use different formats for names, dates, and locations. Robust transformation logic is needed to standardize the data.
- Changing Source Systems: APIs, file formats, and databases evolve, requiring continuous adaptation.
- Real-Time vs Batch: Mixing real-time and batch data introduces syncing and time lag issues.
- Volume Handling: High-volume data sources like clickstreams or sensors need systems that scale without choking.
- Data Quality: Errors like duplicates or corrupt files need automated validation checks to ensure smooth integration.
Data integration often takes up 80% of the effort in a data warehouse.
2. Managing Large Data Volumes
- Storage Optimization: Partitioning and compression help manage large data volumes, but archiving older data can reduce costs.
- Query Performance: As data grows, queries slow down. Indexing and summary tables are essential for maintaining speed.
- Load and Maintenance Windows: Longer data loads and backups can affect business hours, so optimization is crucial.
- Data Tiering: Not all data needs fast access. Cold data can be archived, saving on storage costs.
- Scaling Infrastructure: On-prem scaling is difficult; cloud options are more flexible but can lead to cost spikes.
3. Cost vs. Performance Considerations
- Infrastructure and Licensing: Traditional enterprise data warehouses are expensive to maintain. Cloud options help, but scaling too quickly can increase costs.
- Optimization Efforts: Sometimes improving performance just means developer time spent on tuning queries or models.
- User Expectations: Users often expect sub-second responses, which can increase costs. Managing these expectations helps avoid overspending.
- Cost Transparency: Inefficient queries in the cloud can silently inflate costs. Governance and cost monitoring tools are needed to keep budgets in check.
- Scalability: Some solutions work at 1TB but become costly at 100TB. Early architecture decisions should anticipate rapid growth.
4. Ensuring Data Quality and Consistency
- Issue Detection: Manual detection isn’t sustainable. Automated validation and monitoring tools help identify and fix issues.
- Data Consistency: Conflicting data across departments can cause confusion. Governance and clear definitions help maintain consistency.
- Data Drift: As business definitions evolve, keeping track of these changes requires strong documentation and collaboration.
- Automation Tools: Data observability tools help spot anomalies early, but fine-tuning them can add complexity.
Without proper data quality management, trust in the warehouse erodes.
5. Security and Compliance Requirements
- Regulatory Compliance: Laws like GDPR and HIPAA require encryption, audit trails, and data localization. Your architecture must meet these standards.
- Access Management: Maintaining secure, least-privilege access grows harder as data access expands. Regular audits are crucial.
- Balancing Usability and Security: Strict security can limit usability. Techniques like anonymization help provide a balance.
- Incident Response: Quick detection of unusual activities and integration with security tools are key to mitigating breaches.
Security and compliance require ongoing attention to avoid legal and reputational risks.
Case Studies and Real-World Examples
To understand data warehouse architecture better, let’s look at two real-world implementations. The details vary, but the core lessons apply broadly.
Successful Data Warehouse Implementations
Case 1: Legacy to Cloud Modernization
A financial services firm migrated its aging on-prem Oracle system to Snowflake. The old setup was slow and costly. During the move, they adopted ELT using Matillion, redesigned their schema, and eliminated redundant marts. Real-time pipelines using Kafka and Kinesis were added for time-sensitive data.
Post-migration, query times dropped from hours to seconds. Cloud scalability helped manage cost spikes during reporting periods. A data observability layer caught issues early—like a source schema change that could’ve led to lost data. Executive buy-in and department collaboration were key to adoption and long-term success.
Case 2: Real-Time Retail Analytics
A growing e-commerce company needed fast insights for pricing and inventory. They used a lakehouse model: raw clickstream data flowed into a cloud data lake and was processed with Databricks. Aggregated insights were pushed into Synapse alongside structured ERP data.
Power BI dashboards gave teams near real-time visibility. They used a Lambda architecture—real-time stream for quick updates, and batch for accuracy. A data quality dashboard flagged anomalies, ensuring trust in the data. This agility helped the business act fast, cut costs, and grow revenue—proving that mid-sized firms can achieve enterprise-grade analytics.
Lessons Learned and Key Takeaways
Business Alignment is Critical: Success came from solving real business problems. Stakeholders were involved early, guiding architecture decisions.
Modern Architectures Bring Agility: Cloud and real-time tools made scaling easier, enabling faster integration of new sources.
Data Quality and Observability Pay Off: Both cases used automated monitoring to catch issues early and maintain trust—critical for long-term reliability.
Don’t Neglect Change Management: Involving users and training them eased the transition. Early wins helped build momentum.
Optimize Continuously: Both companies kept refining their systems—cost management, streaming vs. batch balance, and query efficiency.
Choose the Right Mix of Technologies: Tech choices were tailored to needs—Snowflake and ELT for finance; streaming and big data tools for retail.
In short, thoughtful architecture tied to business goals drives real impact. But success also depends on execution—governance, quality, and people all play a role.
Conclusion
Data warehouse architecture sits at the center of how modern organizations manage and use their data. Whether built on-prem or in the cloud, the goal is clear: bring all your data together, make sense of it, and deliver it in a way that helps people take action. It’s not just a backend concern — it directly shapes how teams across the business access insight and make decisions.
We’ve looked at how architecture has evolved, and it’s clear the shift toward cloud, real-time processing, and distributed models isn’t just a trend — it’s a response to growing complexity and expectations. While the tools have changed, the fundamentals still matter. You need a clean structure, quality data, and a setup that can grow with you. Technologies like Snowflake and Databricks make a lot of things easier, but they don’t remove the need for thoughtful design.
Most importantly, an enterprise data warehouse is only valuable if people trust it. That’s where data quality, observability, and governance come in. When you put those in place — along with solid planning and realistic expectations — you end up with more than just a data system. You build a foundation that supports the business, now and in the future.
FAQs
What is the primary difference between Data Fabric and Data Lake?
The primary difference lies in their purpose and how they manage data. A Data Lake is designed as a central repository for storing large volumes of raw, unprocessed data in its native format. In contrast, a Data Fabric is focused on connecting, integrating, and governing data across distributed environments—making data more accessible, consistent, and actionable, without necessarily moving or duplicating it.
Which is better for real-time data processing, Data Fabric or Data Lake?
Data Fabric is better suited for real-time data processing. Its architecture enables live data access across diverse sources without waiting for batch ingestion. This makes it ideal for use cases where timely insights and quick decision-making are essential. Data Lakes typically rely on batch processing, which may introduce delays in accessing up-to-date data.
Can a Data Lake be integrated with a Data Fabric?
Yes, absolutely. Data Fabrics are designed to connect to existing systems, including Data Lakes. By layering a Data Fabric over a Data Lake, organizations can gain better visibility, governance, and access to the raw data stored within the lake—without needing to move it. This combination allows teams to leverage the scalability of a Data Lake and the intelligence of a Data Fabric simultaneously.
Can a Data Lake be integrated with a Data Fabric?
Data Lakes often lack built-in governance, making it harder to track, understand, or trust data—especially without a strong metadata strategy. In contrast, Data Fabric includes automated governance features like data lineage, access controls, and metadata management. This makes it easier to maintain trusted, compliant, and discoverable data across the organization.
What are the key use cases for Data Fabric and Data Lake in data management?
Data Lake is ideal for:
- Storing massive volumes of raw or historical data
- Powering machine learning models
- Data archival and backup
- Prepping data for BI/reporting
Data Fabric is ideal for:
- Real-time access across siloed systems
- Connecting distributed data without physical movement
- Enabling governed self-service analytics
- Accelerating insights without rebuilding infrastructure