![]()
DQLabs Named
A Visionary
in the 2025 Gartner® Magic Quadrant™ For Augmented Data Quality Solutions
Download the ReportGARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
Agentic AI
Data Observability and Data
Quality Platform
Deliver reliable and accurate data for better business outcomes.
Book a DemoTrusted By Modern Data Teams Worldwide






Observe-Measure-Discover-Remediate
the data
that matters
The DQLabs platform harnesses the combined power of Data Observability, Data Quality and Data Discovery to enable data producers, consumers, and leaders to turn data into action faster, easier, and more collaboratively.
Remediate
Augmented, plus GenAI enabled remediation combined with the power of semantics.
Analyst Research
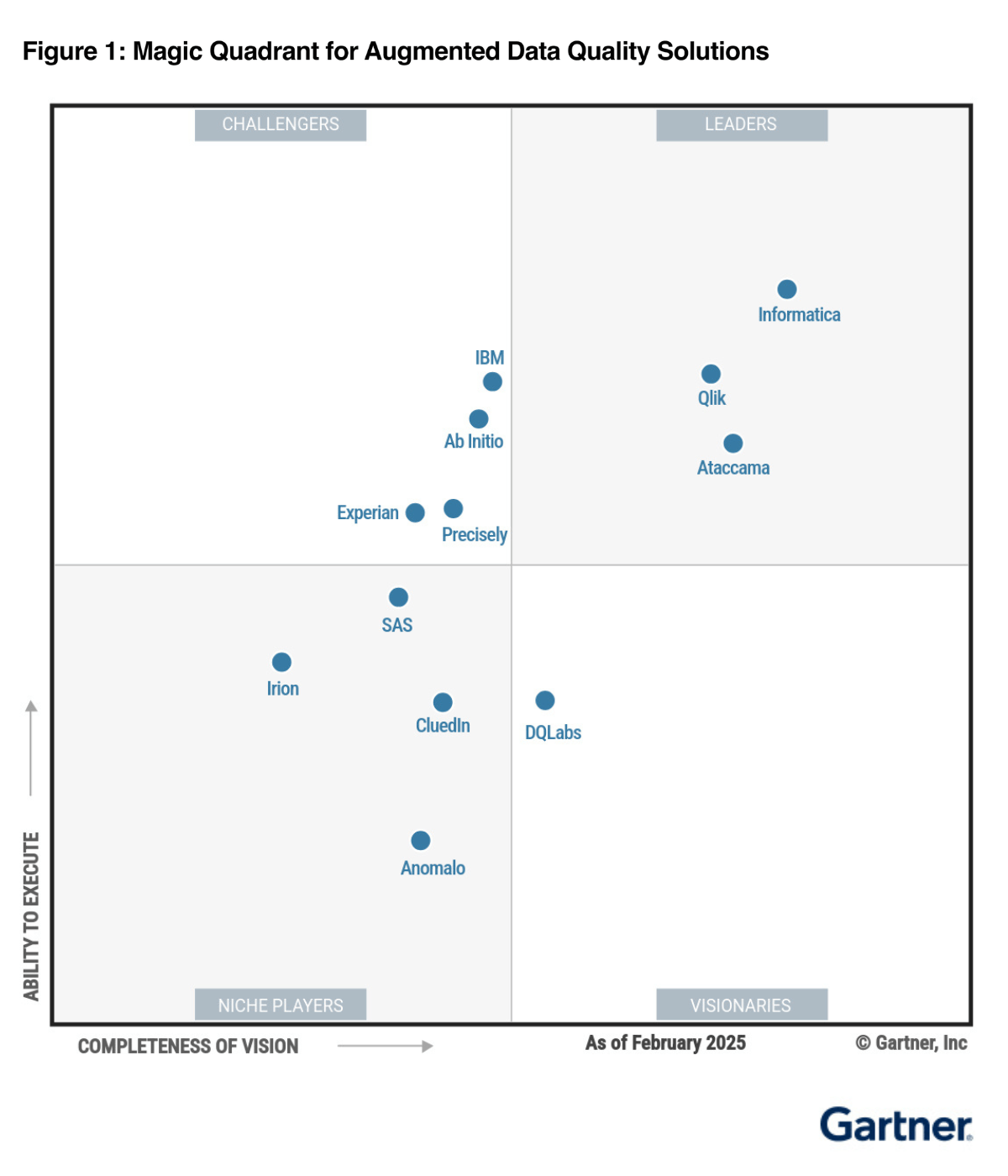
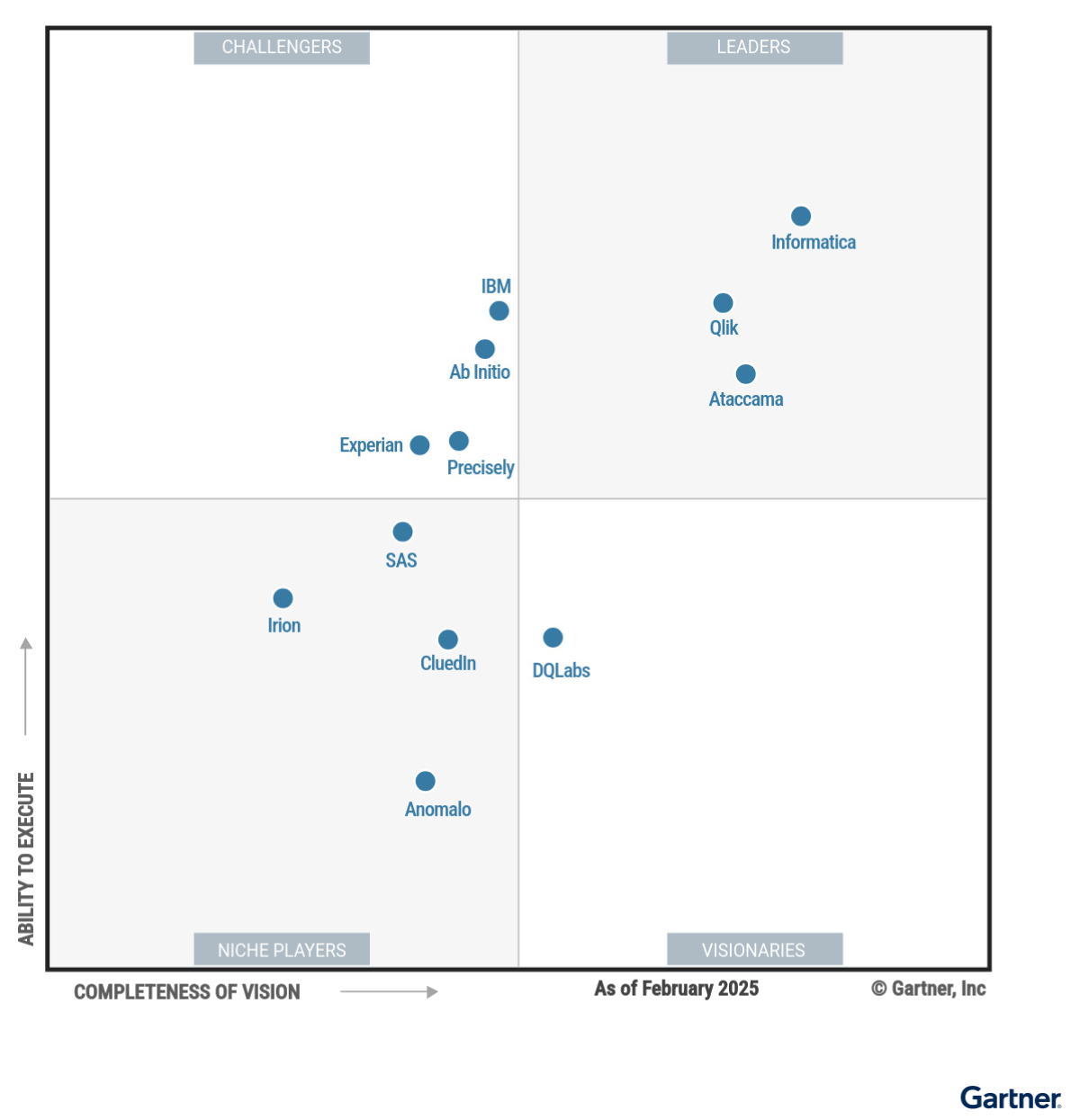
DQLabs is A Visionary in the 2025 Gartner® Magic Quadrant™ for Augmented Data Quality Solutions
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
Data Reliability
Improve data trustworthiness for critical decisions using automated data monitoring and notifying data engineers of reliability issues.
Business Quality
Improve confidence in consumption using business outcome-focused checks across processes, process owners, and data stewards.
Domain Driven Resolution
Leverage principles of domain ownership to auto-discover rules, standardized reference data, issue resolution, and business terms.
Fully Automated
Modernize your data infrastructure in minutes using ML-powered, no-code data quality checks.
Performance Delivered
Deliver millions of checks across petabytes of data across lakes and warehouses in seconds.
Security Compliant
SOC Type 2 compliant platform in a highly secure infrastructure with no customer data retrieval.