
Data Quality
Continuously improve the accuracy of data in business processes, applications, data, and analytic platforms for improved productivity and positive business outcomes.

Gartner Listed DQLabs in the Augmented Data Quality Category as Part of the “2023 Planning Guide for Data Management.”
Out-of-the-box Quality Checks
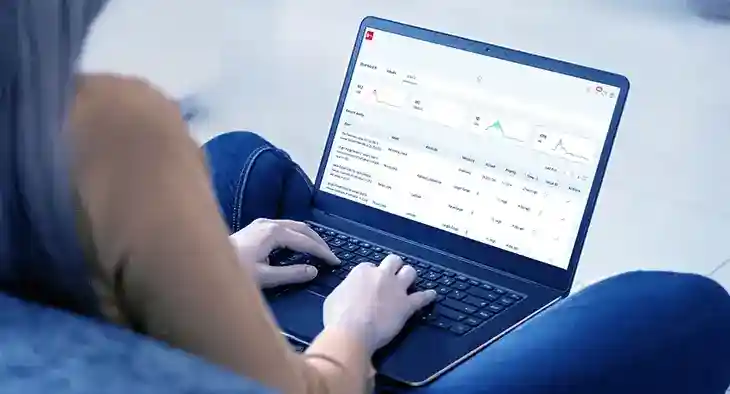
Leverage 50-plus data quality measures across health, frequency, distribution, and statistical categories with dimensions based on the criticality of data to improve accuracy toward business outcomes.
Auto Discover Rules For Speed
Leverage centralized and consistent business quality checks using DQLabs automated rules discovery.
Agile Quality Stewardship
Maintain data to business integrity with standardized business terms, data quality dimensions, domain-based aggregation, scorecards, issue management, and reporting – all in one platform
See Data Quality in Action
Improve the business validation of your data for better outcomes.
More Features from DQLabs Platform
Leverage DQLabs’ unified platform with smart capabilities across data observability, quality, and discovery.
Checks with Auto threshold
Smart data quality and observability monitoring capabilities adjust and adapt automatically for actionable alerts
Read More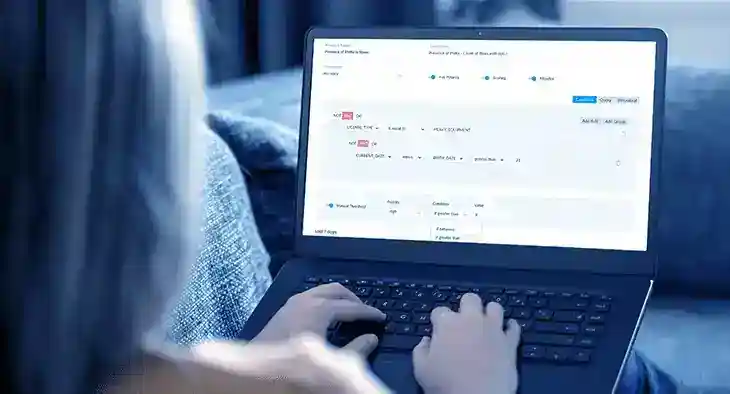
Out of the box Observability
Out-of-the-box advanced anomaly detection algorithm detects anomalies across all metadata and custom measures.
Read More
Semantic Discovery
Discover and extract semantics across your data store with just a few clicks for auto-discovery of rules or active metadata management.
Read More